Jump to the full list of publications here
Highlighted publications
DAC: Quantized Optimal Transport Reward-based Reinforcement Learning Approach to Detoxify Query Auto-Completion
[July, 2024]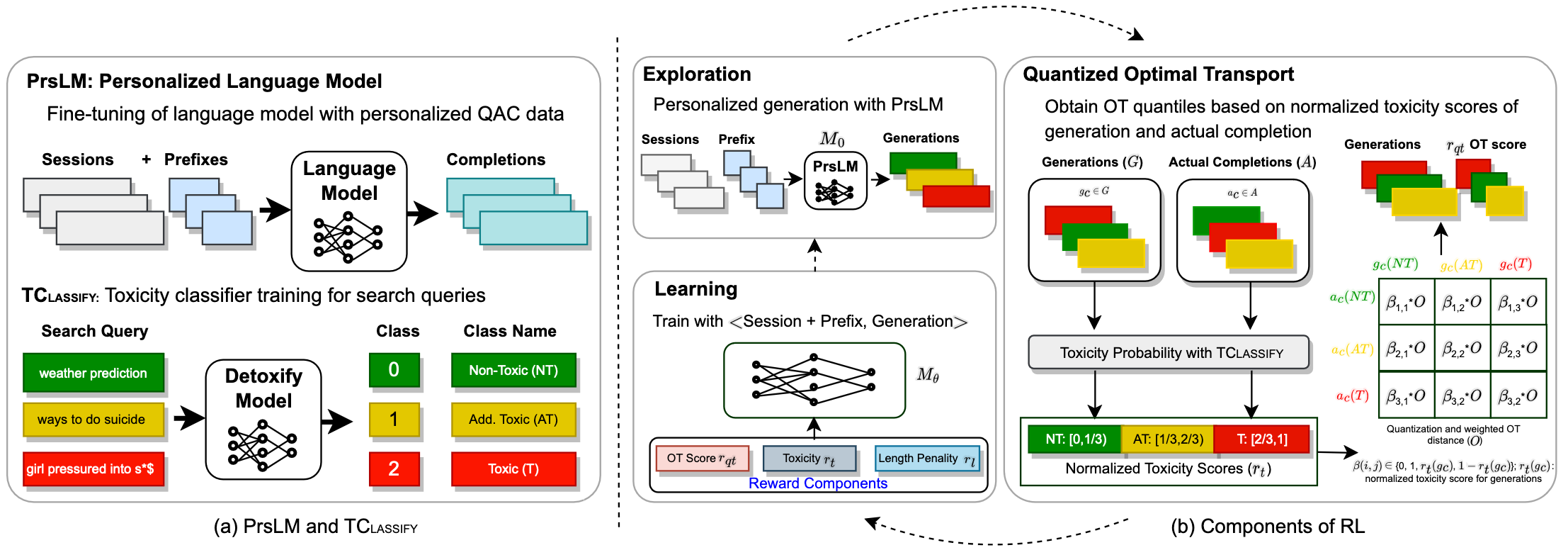
Modern Query Auto-Completion (QAC) systems utilize natural language generation (NLG) using large language models (LLM) to achieve remarkable performance. However, these systems are prone to generating biased and toxic completions due to inherent learning biases. Existing detoxification approaches exhibit two key limitations: (1) They primarily focus on mitigating toxicity for grammatically well-formed long sentences but struggle to adapt to the QAC task, where queries are short and structurally different (include spelling errors, do not follow grammatical rules and have relatively flexible word order). (2) These approaches often view detoxification through a binary lens where all text labeled as toxic is undesirable and non-toxic is considered desirable. To address these limitations, we propose DAC, an intuitive and efficient reinforcement learning-based model to detoxify QAC. With DAC, we introduce an additional perspective of considering the third query class of addressable toxicity. These queries can encompass implicit toxicity, subjective toxicity, or non-toxic queries containing toxic words. We incorporate this three-class query behavior perspective into the proposed model through quantized optimal transport to learn distinctions and generate truly non-toxic completions. We evaluate toxicity levels in the generated completions by DAC across two real-world QAC datasets (Bing and AOL) using two classifiers: a publicly available generic classifier (Detoxify) and a search query-specific classifier, which we develop (TClassify). we find that DAC consistently outperforms all existing baselines on the Bing dataset and achieves competitive performance on the AOL dataset for query detoxification. % providing high quality and low toxicity. We make the code and models publicly available.
47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2024)
Modern Query Auto-Completion (QAC) systems utilize natural language generation (NLG) using large language models (LLM) to achieve remarkable performance. However, these systems are prone to generating biased and toxic completions due to inherent learning biases. Existing detoxification approaches exhibit two key limitations: (1) They primarily focus on mitigating toxicity for grammatically well-formed long sentences but struggle to adapt to the QAC task, where queries are short and structurally different (include spelling errors, do not follow grammatical rules and have relatively flexible word order). (2) These approaches often view detoxification through a binary lens where all text labeled as toxic is undesirable and non-toxic is considered desirable. To address these limitations, we propose DAC, an intuitive and efficient reinforcement learning-based model to detoxify QAC. With DAC, we introduce an additional perspective of considering the third query class of addressable toxicity. These queries can encompass implicit toxicity, subjective toxicity, or non-toxic queries containing toxic words. We incorporate this three-class query behavior perspective into the proposed model through quantized optimal transport to learn distinctions and generate truly non-toxic completions. We evaluate toxicity levels in the generated completions by DAC across two real-world QAC datasets (Bing and AOL) using two classifiers: a publicly available generic classifier (Detoxify) and a search query-specific classifier, which we develop (TClassify). we find that DAC consistently outperforms all existing baselines on the Bing dataset and achieves competitive performance on the AOL dataset for query detoxification. % providing high quality and low toxicity. We make the code and models publicly available.
Trie-NLG: Trie Context Augmentation to Improve Personalized Query Auto-Completion for Short and Unseen Prefixes
[July, 2023]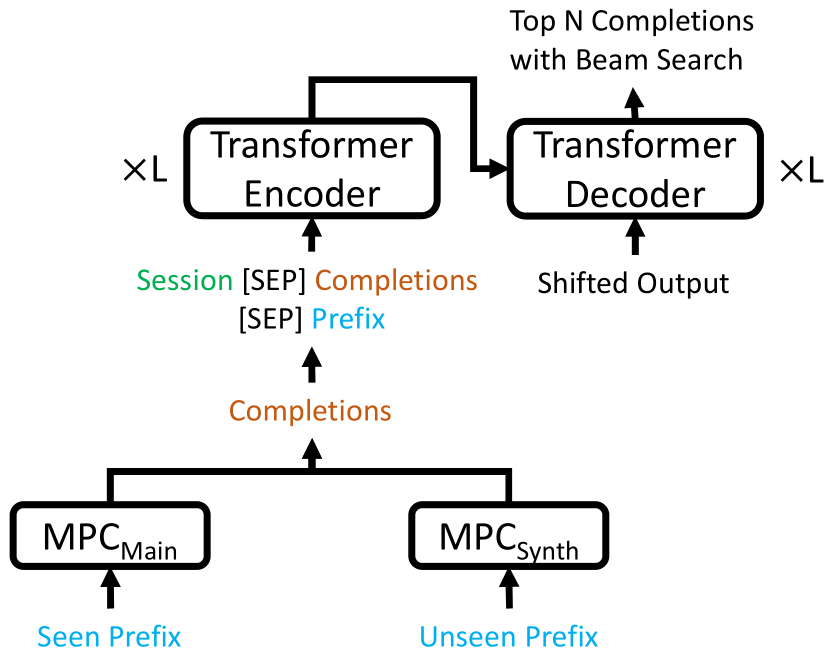
Query auto-completion (QAC) aims at suggesting plausible completions for a given query prefix. Traditionally, QAC systems have leveraged tries curated from historical query logs to suggest most popular completions. In this context, there are two specific scenarios that are difficult to handle for any QAC system: short prefixes (which are inherently ambiguous) and unseen prefixes. Recently, personalized Natural Language Generation (NLG) models have been proposed to leverage previous session queries as context for addressing these two challenges. However, such NLG models suffer from two drawbacks: (1) some of the previous session queries could be noisy and irrelevant to the user intent for the current prefix, and (2) NLG models cannot directly incorporate historical query popularity. We propose a novel NLG model for QAC, Trie-NLG, which jointly leverages popularity signals from trie and personalization signals from previous session queries. We train the Trie-NLG model by augmenting the prefix with rich context comprising of recent session queries and top trie completions. This simple modeling approach overcomes the limitations of trie-based and NLG-based approaches and leads to state-of-the-art performance. We evaluate the Trie-NLG model using two large QAC datasets. On average, our model achieves huge ∼57% and ∼14% boost in MRR over the popular trie-based lookup and the strong BART-based baseline methods, respectively.
Journal track at European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD 2023)
Query auto-completion (QAC) aims at suggesting plausible completions for a given query prefix. Traditionally, QAC systems have leveraged tries curated from historical query logs to suggest most popular completions. In this context, there are two specific scenarios that are difficult to handle for any QAC system: short prefixes (which are inherently ambiguous) and unseen prefixes. Recently, personalized Natural Language Generation (NLG) models have been proposed to leverage previous session queries as context for addressing these two challenges. However, such NLG models suffer from two drawbacks: (1) some of the previous session queries could be noisy and irrelevant to the user intent for the current prefix, and (2) NLG models cannot directly incorporate historical query popularity. This motivates us to propose a novel NLG model for QAC, Trie-NLG, which jointly leverages popularity signals from trie and personalization signals from previous session queries. We train the Trie-NLG model by augmenting the prefix with rich context comprising of recent session queries and top trie completions. This simple modeling approach overcomes the limitations of trie-based and NLG-based approaches and leads to state-of-the-art performance. We evaluate the Trie-NLG model using two large QAC datasets. On average, our model achieves huge ∼57% and ∼14% boost in MRR over the popular trie-based lookup and the strong BART-based baseline methods, respectively.
Dial-M: A Masking-based Framework for Dialogue Evaluation
[July, 2023]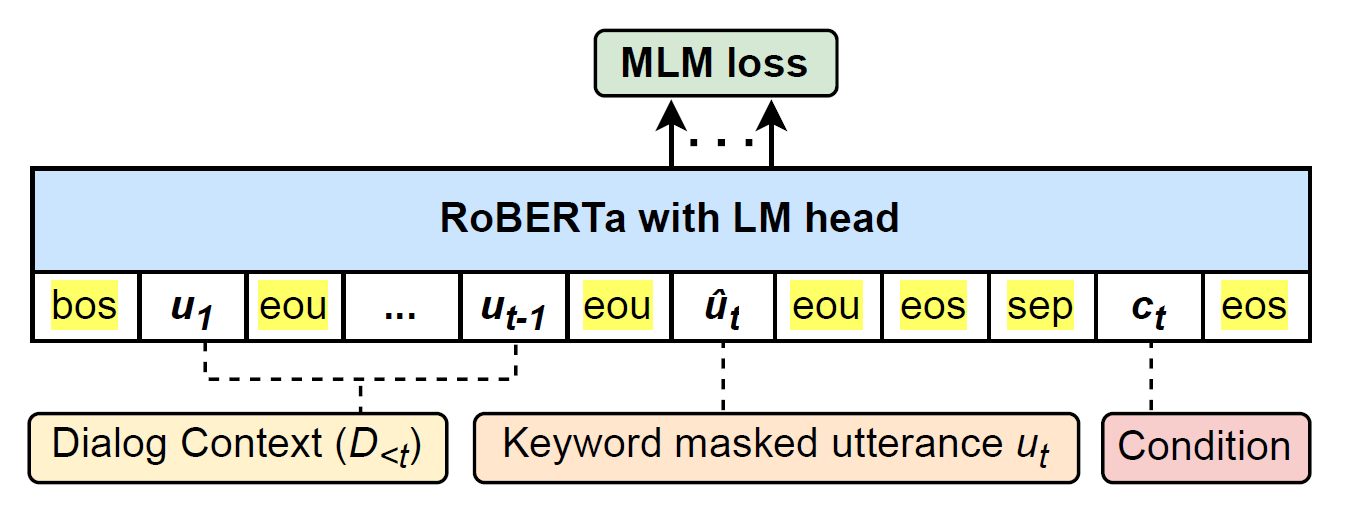
We propose Dial-M, a Masking-based reference-free framework for Dialogue evaluation. The main idea is to mask the keywords of the current utterance and predict them, given the dialogue history and various conditions (like knowledge, persona, etc.), thereby making the evaluation framework simple and easily extensible for multiple datasets. Regardless of its simplicity, Dial-M achieves comparable performance to state-of-the-art metrics on several dialogue evaluation datasets. We also discuss the interpretability of our proposed metric along with error analysis.
24th Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL 2023)
In dialogue systems, automatically evaluating machine-generated responses is critical and challenging. Despite the tremendous progress in dialogue generation research, its evaluation heavily depends on human judgments. The standard word-overlapping based evaluation metrics are ineffective for dialogues. As a result, most of the recently proposed metrics are model-based and reference-free, which learn to score different aspects of a conversation. However, understanding each aspect requires a separate model, which makes them computationally expensive. To this end, we propose Dial-M, a Masking-based reference-free framework for Dialogue evaluation. The main idea is to mask the keywords of the current utterance and predict them, given the dialogue history and various conditions (like knowledge, persona, etc.), thereby making the evaluation framework simple and easily extensible for multiple datasets. Regardless of its simplicity, Dial-M achieves comparable performance to state-of-the-art metrics on several dialogue evaluation datasets. We also discuss the interpretability of our proposed metric along with error analysis.
DivHSK: Diverse Headline Generation using Self-Attention based Keyword Selection
[July, 2023]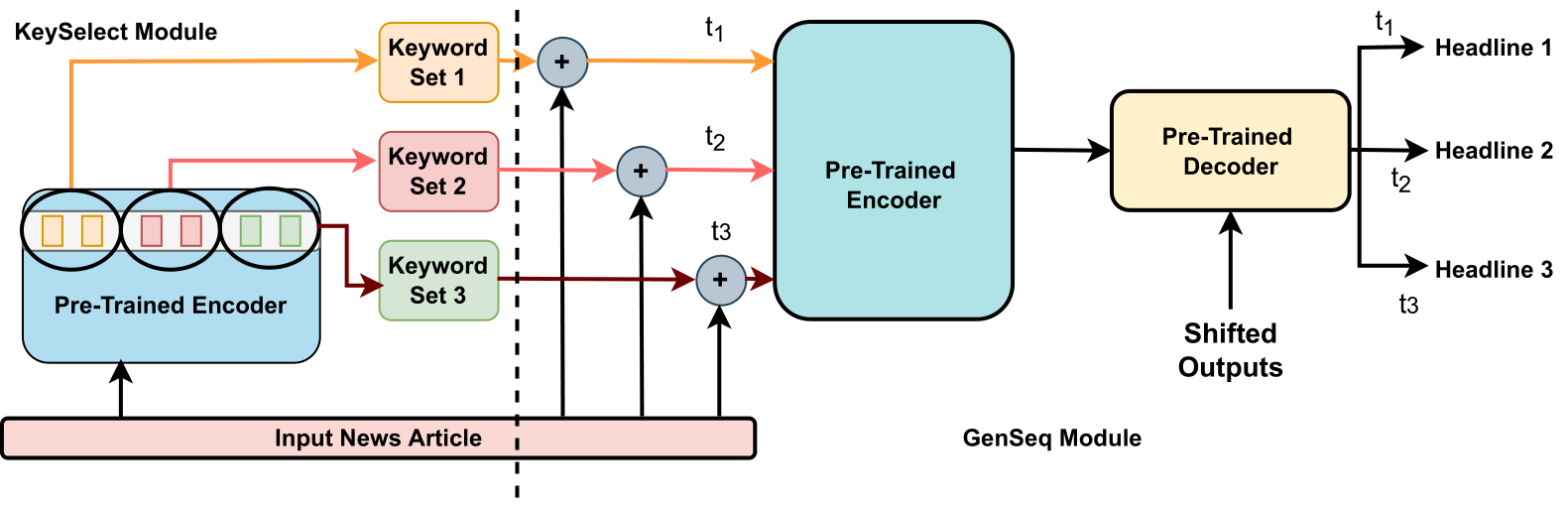
Diverse headline generation is an NLP task where given a news article, the goal is to generate multiple headlines that are true to the content of the article but are different among themselves. This task aims to exhibit and exploit semantically similar one-to-many relationships between a source news article and multiple target headlines. Toward this, we propose a novel model called DIVHSK. It has two components:KEYSELECT for selecting the important keywords, and SEQGEN, for finally generating the multiple diverse headlines. In KEYSELECT, we cluster the self-attention heads of the last layer of the pre-trained encoder and select the most-attentive theme and general keywords from the source article. Then, cluster-specific keyword sets guide the SEQGEN, a pre-trained encoder-decoder model, to generate diverse yet semantically similar headlines. The proposed model consistently outperformed existing literature and our strong baselines and emerged as a state-of-the-art model. We have also created a high-quality multi-reference headline dataset from news articles.
61st Annual Meeting of the Association for Computational Linguistics (ACL 2023)
Diverse headline generation is an NLP task where given a news article, the goal is to generate multiple headlines that are true to the content of the article, but are different among themselves. This task aims to exhibit and exploit semantically similar one-to-many relationships between a source news article and multiple target headlines. Towards this, we propose a novel model called DIVHSK. It has two components: KEYSELECT for selecting the important keywords, and SEQGEN, for finally generating the multiple diverse headlines. In KEYSELECT, we cluster the self-attention heads of the last layer of the pre-trained encoder and select the mostattentive theme and general keywords from the source article. Then, cluster-specific keyword sets guide the SEQGEN, a pre-trained encoderdecoder model, to generate diverse yet semantically similar headlines. The proposed model consistently outperformed existing literature and our strong baselines and emerged as a stateof-the-art model. Additionally, We have also created a high-quality multi-reference headline dataset from news articles
Towards Fair Evaluation of Dialogue State Tracking by Flexible Incorporation of Turn-level Performances
[May, 2022]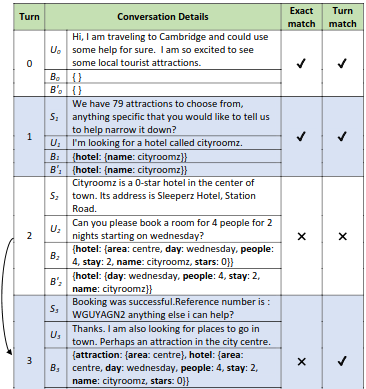
Dialogue State Tracking (DST) is primarily evaluated using Joint Goal Accuracy (JGA) defined as the fraction of turns where the groundtruth dialogue state exactly matches the prediction. We propose a new evaluation metric named Flexible Goal Accuracy (FGA). FGA is a generalized version of JGA. But unlike JGA, it tries to give penalized rewards to mispredictions that are locally correct i.e. the root cause of the error is an earlier turn. By doing so, FGA considers the performance of both cumulative and turn-level prediction flexibly and provides a better insight than the existing metrics. We also show that FGA is a better discriminator of DST model performance.
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers)
Dialogue State Tracking (DST) is primarily evaluated using Joint Goal Accuracy (JGA) defined as the fraction of turns where the ground-truth dialogue state exactly matches the prediction. Generally in DST, the dialogue state or belief state for a given turn contain all the intents shown by the user till that turn. Due to this cumulative nature of the belief state, it is difficult to get a correct prediction once a misprediction has occurred. Thus, although being a useful metric, it can be harsh at times and underestimate the true potential of a DST model. Moreover, an improvement in JGA can sometimes decrease the performance of turn-level or non-cumulative belief state prediction due to inconsistency in annotations. So, using JGA as the only metric for model selection may not be ideal for all scenarios. In this work, we discuss various evaluation metrics used for DST along with their shortcomings. To address the existing issues, we propose a new evaluation metric named Flexible Goal Accuracy (FGA). FGA is a generalized version of JGA. But unlike JGA, it tries to give penalized rewards to mispredictions that are locally correct i.e. the root cause of the error is an earlier turn. By doing so, FGA considers the performance of both cumulative and turn-level prediction flexibly and provides a better insight than the existing metrics. We also show that FGA is a better discriminator of DST model performance.
Towards Robust and Semantically Organised Latent Representations for Unsupervised Text Style Transfer
[May, 2022]We introduce EPAAEs (Embedding Perturbed Adversarial AutoEncoders) which completes this perturbation model, by adding a finely adjustable noise component on the continuous embeddings space. We empirically show that this (a) produces a better organised latent space that clusters stylistically similar sentences together, (b) performs best on a diverse set of text style transfer tasks than similar denoising-inspired baselines, and (c) is capable of fine-grained control of Style Transfer strength.
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
Recent studies show that auto-encoder based approaches successfully perform language generation, smooth sentence interpolation, and style transfer over unseen attributes using unlabelled datasets in a zero-shot manner. The latent space geometry of such models is organised well enough to perform on datasets where the style is 'coarse-grained' i.e. a small fraction of words alone in a sentence are enough to determine the overall style label. A recent study uses a discrete token-based perturbation approach to map 'similar' sentences ('similar' defined by low Levenshtein distance/ high word overlap) close by in latent space. This definition of 'similarity' does not look into the underlying nuances of the constituent words while mapping latent space neighbourhoods and therefore fails to recognise sentences with different style-based semantics while mapping latent neighbourhoods. We introduce EPAAEs (Embedding Perturbed Adversarial AutoEncoders) which completes this perturbation model, by adding a finely adjustable noise component on the continuous embeddings space. We empirically show that this (a) produces a better organised latent space that clusters stylistically similar sentences together, (b) performs best on a diverse set of text style transfer tasks than similar denoising-inspired baselines, and (c) is capable of fine-grained control of Style Transfer strength. We also extend the text style transfer tasks to NLI datasets and show that these more complex definitions of style are learned best by EPAAE. To the best of our knowledge, extending style transfer to NLI tasks has not been explored before.
Meta-XNLG: A Meta-Learning Approach Based on Language Clustering for Zero-Shot Cross-Lingual Transfer and Generation
[May, 2022]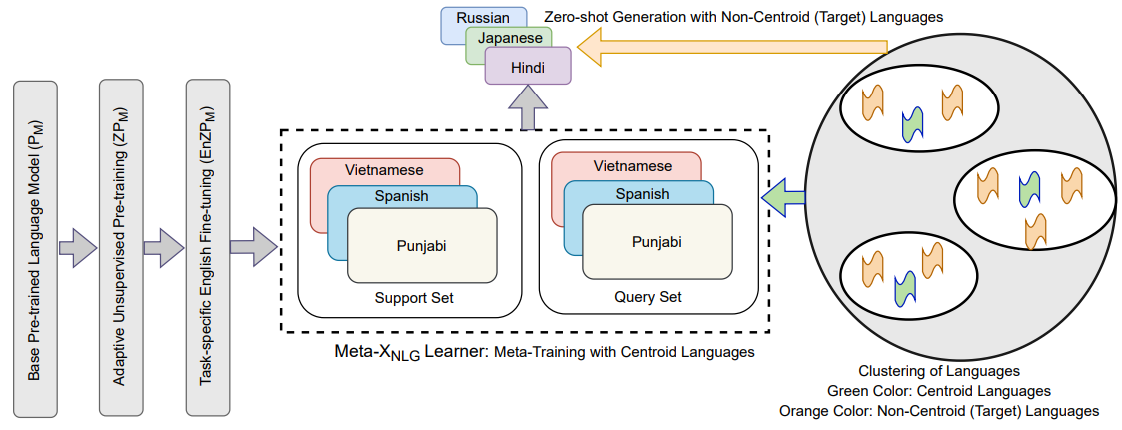
We propose a novel meta-learning framework (called Meta-XNLG) to learn shareable structures from typologically diverse languages based on meta-learning and language clustering. This is a step towards uniform cross-lingual transfer for unseen languages. We first cluster the languages based on language representations and identify the centroid language of each cluster. Then, a meta-learning algorithm is trained with all centroid languages and evaluated on the other languages in the zero-shot setting.
Findings of the Association for Computational Linguistics, ACL 2022
Recently, the NLP community has witnessed a rapid advancement in multilingual and cross-lingual transfer research where the supervision is transferred from high-resource languages (HRLs) to low-resource languages (LRLs). However, the cross-lingual transfer is not uniform across languages, particularly in the zero-shot setting. Towards this goal, one promising research direction is to learn shareable structures across multiple tasks with limited annotated data. The downstream multilingual applications may benefit from such a learning setup as most of the languages across the globe are low-resource and share some structures with other languages. In this paper, we propose a novel meta-learning framework (called Meta-X$_{NLG}$) to learn shareable structures from typologically diverse languages based on meta-learning and language clustering. This is a step towards uniform cross-lingual transfer for unseen languages. We first cluster the languages based on language representations and identify the centroid language of each cluster. Then, a meta-learning algorithm is trained with all centroid languages and evaluated on the other languages in the zero-shot setting. We demonstrate the effectiveness of this modeling on two NLG tasks (Abstractive Text Summarization and Question Generation), 5 popular datasets and 30 typologically diverse languages. Consistent improvements over strong baselines demonstrate the efficacy of the proposed framework. The careful design of the model makes this end-to-end NLG setup less vulnerable to the accidental translation problem, which is a prominent concern in zero-shot cross-lingual NLG tasks.
Unsupervised Domain Adaptation With Global and Local Graph Neural Networks Under Limited Supervision and Its Application to Disaster Response
[March, 2022]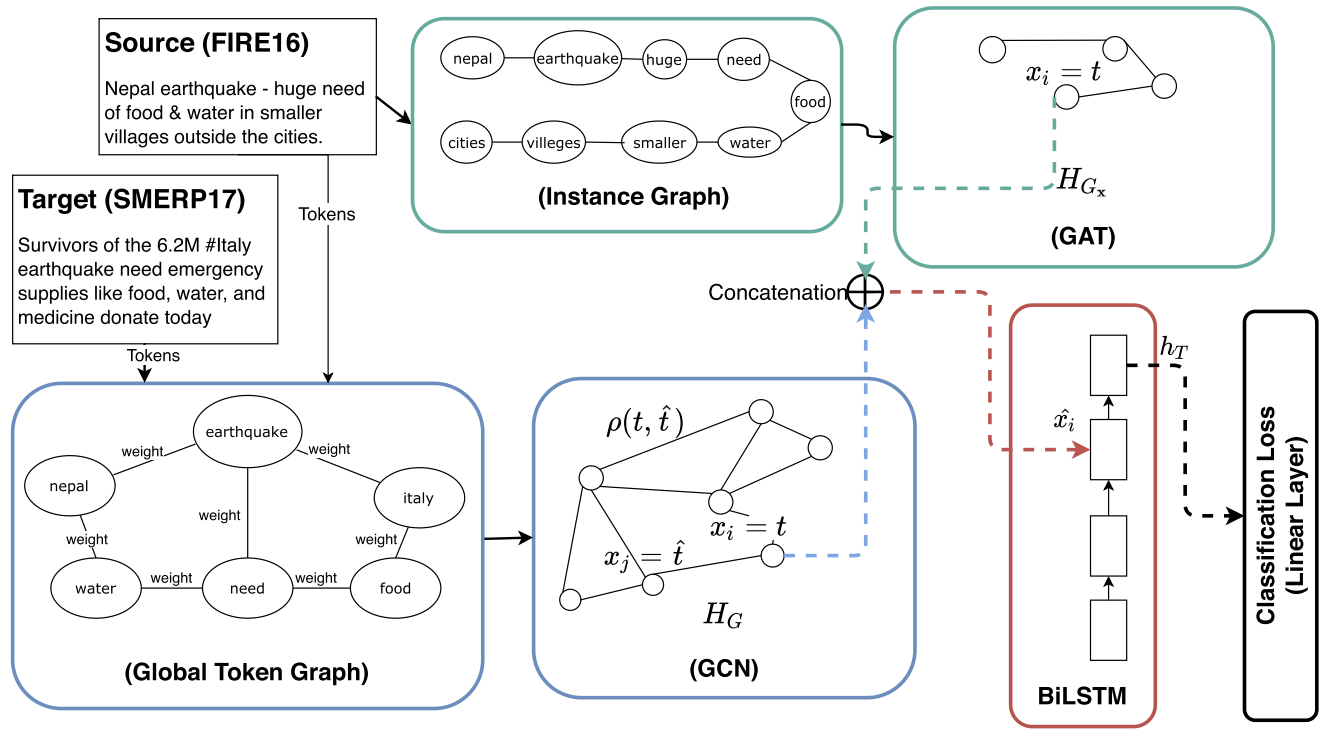
In our experiments, we show that the proposed method outperforms state-of-the-art techniques by 2.74% weighted F1 score on average on two standard public datasets in the area of disaster management. We also report experimental results for granular actionable multilabel classification datasets in disaster domain for the first time, on which we outperform BERT by 3.00% on average w.r.t. weighted F1.
IEEE Transactions on Computational Social Systems (Volume: 10, Issue: 2, April 2023)
Identification and categorization of social media posts generated during disasters are crucial to reduce the suffering of the affected people. However, the lack of labeled data is a significant bottleneck in learning an effective categorization system for a disaster. This motivates us to study the problem as unsupervised domain adaptation (UDA) between a previous disaster with labeled data (source) and a current disaster (target). However, if the amount of labeled data available is limited, it restricts the learning capabilities of the model. To handle this challenge, we use limited labeled data along with abundantly available unlabeled data, generated during a source disaster to propose a novel two-part graph neural network (GNN). The first part extracts domain-agnostic global information by constructing a token-level graph across domains and the second part preserves local instance-level semantics. In our experiments, we show that the proposed method outperforms state-of-the-art techniques by 2.74% weighted F1 score on average on two standard public datasets in the area of disaster management. We also report experimental results for granular actionable multilabel classification datasets in disaster domain for the first time, on which we outperform BERT by 3.00% on average w.r.t. weighted F1. Additionally, we show that our approach can retain performance when minimal labeled data are available.
ZmBART: An Unsupervised Cross-lingual Transfer Framework for Language Generation
[August, 2021]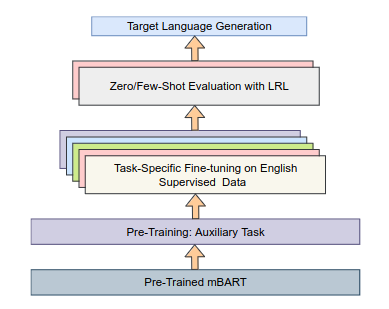
We propose an unsupervised crosslingual language generation framework (called ZmBART) that does not use any parallel or pseudo-parallel/back-translated data. In this framework, we further pre-train mBART sequence-to-sequence denoising auto-encoder model with an auxiliary task using monolingual data of three languages. The objective function of the auxiliary task is close to the target tasks which enriches the multi-lingual latent representation of mBART and provides good initialization for target tasks. Then, this model is fine-tuned with task-specific supervised English data and directly evaluated with low-resource languages in the Zero-shot setting.
Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021
Despite the recent advancement in NLP research, cross-lingual transfer for natural language generation is relatively understudied. In this work, we transfer supervision from high resource language (HRL) to multiple lowresource languages (LRLs) for natural language generation (NLG). We consider four NLG tasks (text summarization, question generation, news headline generation, and distractor generation) and three syntactically diverse languages, i.e., English, Hindi, and Japanese. We propose an unsupervised crosslingual language generation framework (called ZmBART) that does not use any parallel or pseudo-parallel/back-translated data. In this framework, we further pre-train mBART sequence-to-sequence denoising auto-encoder model with an auxiliary task using monolingual data of three languages. The objective function of the auxiliary task is close to the target tasks which enriches the multi-lingual latent representation of mBART and provides good initialization for target tasks. Then, this model is fine-tuned with task-specific supervised English data and directly evaluated with low-resource languages in the Zero-shot setting. To overcome catastrophic forgetting and spurious correlation issues, we applied freezing model component and data argumentation approaches respectively. This simple modeling approach gave us promising results. We experimented with few-shot training (with 1000 supervised data-points) which boosted the model performance further. We performed several ablations and cross-lingual transferability analysis to demonstrate the robustness of ZmBART.
Hi-DST: A Hierarchical Approach for Scalable and Extensible Dialogue State Tracking
[July, 2021]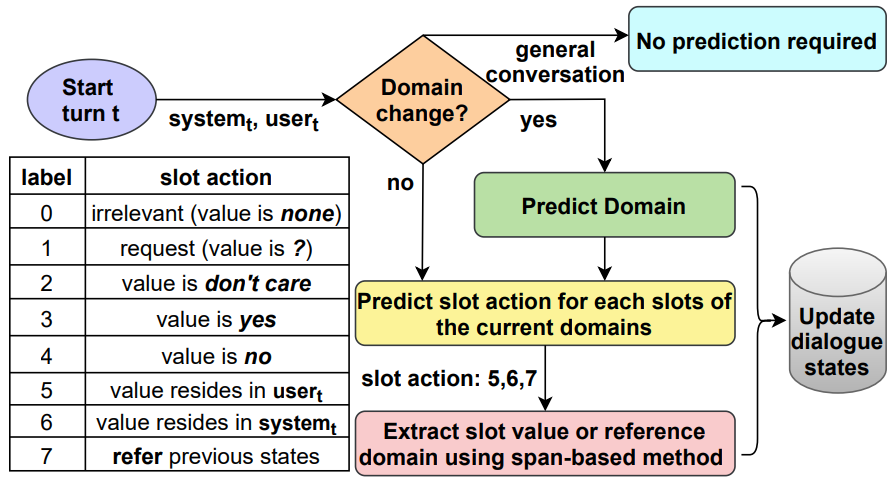
In this work, we propose to address these issues using a Hierarchical DST (Hi-DST) model. At a given turn, the model first detects a change in domain followed by domain prediction if required. Then it decides suitable action for each slot in the predicted domains and finds their value accordingly. The model parameters of Hi-DST are independent of the number of domains/slots. Due to the hierarchical modeling, it achieves O(|M|+|N|) belief state prediction for a single turn where M and N are the set of unique domains and slots respectively.
Proceedings of the 22nd Annual Meeting of the Special Interest Group on Discourse and Dialogue
Dialogue State Tracking (DST) is a sub-task of task-based dialogue systems where the user intention is tracked through a set of (domain, slot, slot-value) triplets. Existing DST models can be difficult to extend for new datasets with larger domains/slots mainly due to either of the two reasons- i) prediction of domain-slot as a pair, and ii) dependency of model parameters on the number of slots and domains. In this work, we propose to address these issues using a Hierarchical DST (Hi-DST) model. At a given turn, the model first detects a change in domain followed by domain prediction if required. Then it decides suitable action for each slot in the predicted domains and finds their value accordingly. The model parameters of Hi-DST are independent of the number of domains/slots. Due to the hierarchical modeling, it achieves O(|M|+|N|) belief state prediction for a single turn where M and N are the set of unique domains and slots respectively. We argue that the hierarchical structure helps in the model explainability and makes it easily extensible to new datasets. Experiments on the MultiWOZ dataset show that our proposed model achieves comparable joint accuracy performance to state-of-the-art DST models.