Publications by Year
Multilingual Tokenization through the Lens of Indian Languages: Challenges and Insights
ACL (April 2026)
Tokenization plays a pivotal role in NLP and is fundamental to training language models. However, existing tokenizers are often skewed towards high-resource languages, limiting their effectiveness for linguistically diverse and morphologically rich languages such as those in the Indian subcontinent. In this work, we present a comprehensive empirical study of multilingual tokenization across 17 Indic languages spanning 11 scripts and two language families. We systematically evaluate the effects of (i) widely used subword algorithms: BPE and Unigram LM, (ii) script and orthography-aware normalization, (iii) vocabulary size, and (iv) multilingual vocabulary construction strategies. We use a combination of intrinsic and extrinsic evaluations to obtain the following observations: (i) script-specific normalization improves tokenization quality, (ii) Unigram LM better preserves morphological boundaries than BPE, (iii) cluster-based vocabulary construction shows improvement in downstream tasks compared to the joint method. Our findings highlight the importance of linguistically informed design choices in multilingual tokenization and offer practical guidance for building effective tokenizers for low-resource and morphologically complex languages.

A Unified View on Emotion Representation in Large Language Models
EACL (March 2026)
Interest in leveraging Large Language Models (LLMs) for emotional support systems motivates the need to understand how these models comprehend and represent emotions internally. While recent works show the presence of emotion concepts in the hidden state representations, it’s unclear if the model has a robust representation that is consistent across different datasets. In this paper, we present a unified view to understand emotion representation in LLMs, experimenting with diverse datasets and prompts. We then evaluate the reasoning ability of the models on a complex emotion identification task. We find that LLMs have a common emotion representation in the later layers of the model, and the vectors capturing the direction of emotions extracted from these representations can be interchanged among datasets with minimal impact on performance. Our analysis of reasoning with Chain of Thought (CoT) prompting shows the limits of emotion comprehension. Therefore, despite LLMs implicitly having emotion representations, they are not equally skilled at reasoning with them in complex scenarios. This motivates the need for further research to find new approaches.
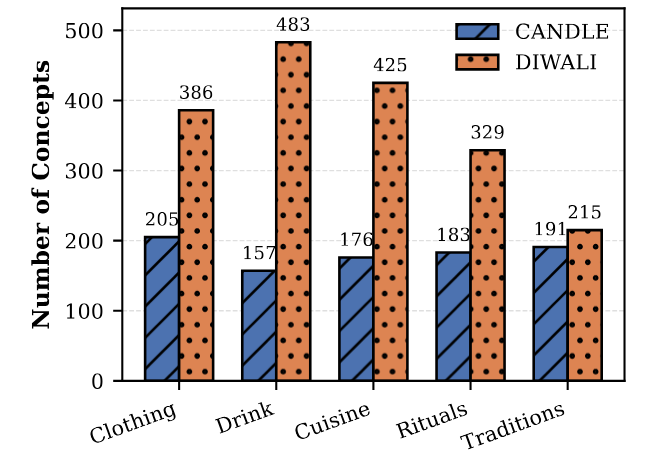
DIWALI - Diversity and Inclusivity aWare cuLture specific Items for India
EMNLP Main (August 2025)
Large language models (LLMs) are used in various applications. However, despite its wide capabilities, it is shown to lack cultural alignment and produce biased generations due to a lack of cultural knowledge and competence. Evaluation of LLMs for cultural awareness and alignment is particularly challenging due to the lack of proper evaluation metrics and the unavailability of culturally grounded datasets representing the vast complexity of cultures at the regional and sub-regional levels. Existing datasets for culture-specific items (CSIs) focus primarily on concepts at regional levels and contain several inconsistencies regarding the cultural attribution of items. To address this issue, we created a novel CSI dataset for Indian culture, belonging to 17 cultural facets. The dataset comprises ~8k cultural concepts from 36 sub-regions. To measure cultural competence, we evaluate the adaptation of LLMs to cultural text using the created CSIs, LLM-based, and human evaluations. Also, we perform quantitative analysis demonstrating selective sub-regional coverage and surface-level adaptations across all considered LLMs.
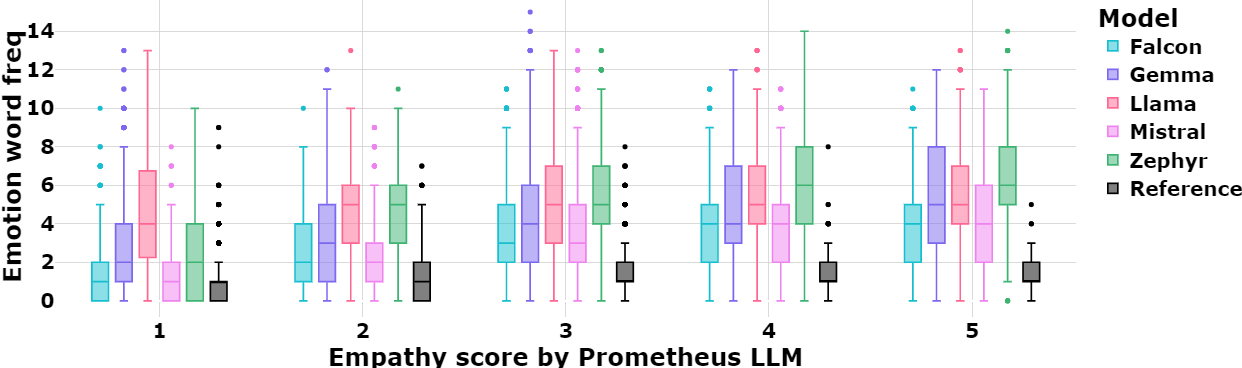
Probing the Inherent Ability of Large Language Models for Generating Empathetic Responses
2025 IEEE Swiss Conference on Data Science (SDS) (June 2025)
Large Language Models (LLMs) have demonstrated capabilities beyond basic text generation, like question answering, translation, and even stylistic text generation. Since these models are available for public use, enormous effort has been put into safety engineering to ensure that undesirable and harmful text is not generated and the generations are polite and empathetic. In this work, we examine the inherent empathy capabilities of five open-source LLMs and evaluate them from multiple angles using automated metrics to understand their capabilities and limitations. In the context of this work, “inherent” refers to the LLM’s ability to generate empathetic text without having to explicitly prompt for it. We examine if empathy is treated as a style change or is the model demonstrating some understanding of the specific user’s context. We find that LLMs use more emotion words than humans in their generations. They can also infer the user’s emotional state, a crucial characteristic of empathy. Due to the probabilistic nature of obtaining generations, there is a tendency for the responses to drift away from the user’s actual intent. In such cases, specific prompting allows the model to respond appropriately. We summarize the differences observed between human and LLM generations and conclude with a potential research direction for empathetic dialog generation that leverages the capabilities of LLMs.
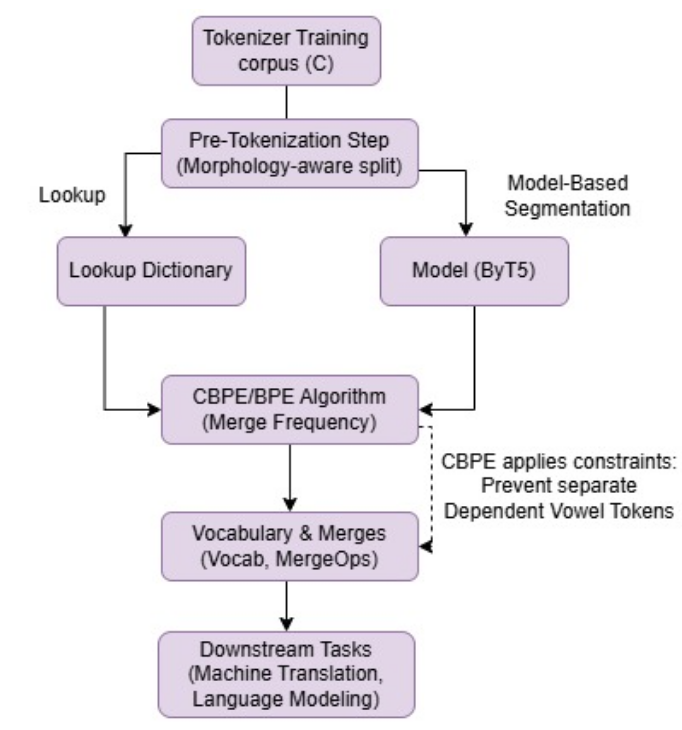
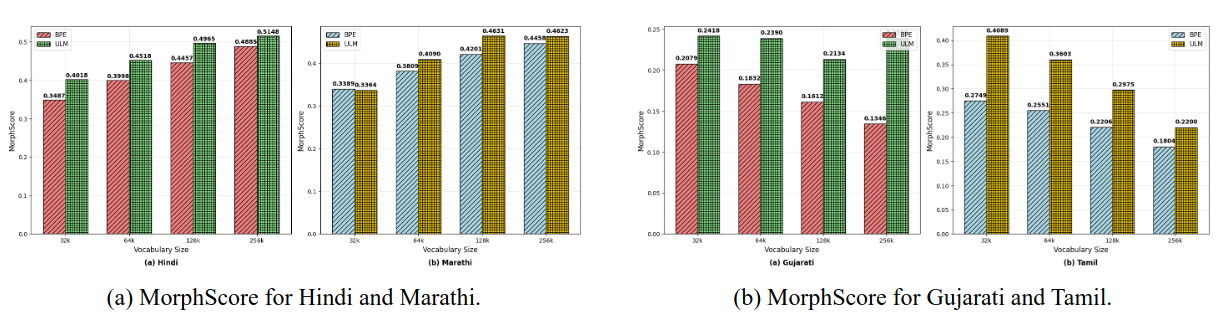
MorphTok: Morphologically Grounded Tokenization for Indic languages
ICML 2025 Tokenization Workshop (TokShop) (June 2025)
Tokenization is a crucial step in NLP, especially with the rise of large language models (LLMs), impacting downstream performance, computational cost, and efficiency. Existing LLMs rely on the classical Byte-pair Encoding (BPE) algorithm for subword tokenization that greedily merges frequent character bigrams, often leading to segmentation that does not align with linguistically meaningful units. To address this, we propose morphology-aware segmentation as a pre-tokenization step before applying BPE. To facilitate morphology-aware segmentation, we create a novel dataset for Hindi and Marathi, incorporating sandhi splitting to enhance the subword tokenization. Experiments on downstream tasks show that morphologically grounded tokenization improves machine translation and language modeling performance. Additionally, to handle the dependent vowels common in syllable-based writing systems used by Indic languages, we propose Constrained BPE (CBPE), an extension to the standard BPE algorithm incorporating script-specific constraints. In particular, CBPE handles dependent vowels to form a cohesive unit with other characters instead of occurring as a single unit. Our results show that CBPE achieves a 1.68% reduction in fertility scores while maintaining comparable or improved downstream performance in machine translation and language modeling, offering a computationally efficient alternative to standard BPE. Moreover, to evaluate segmentation across different tokenization algorithms, we introduce a new human evaluation metric, \textit{EvalTok}, enabling more human-grounded assessment.
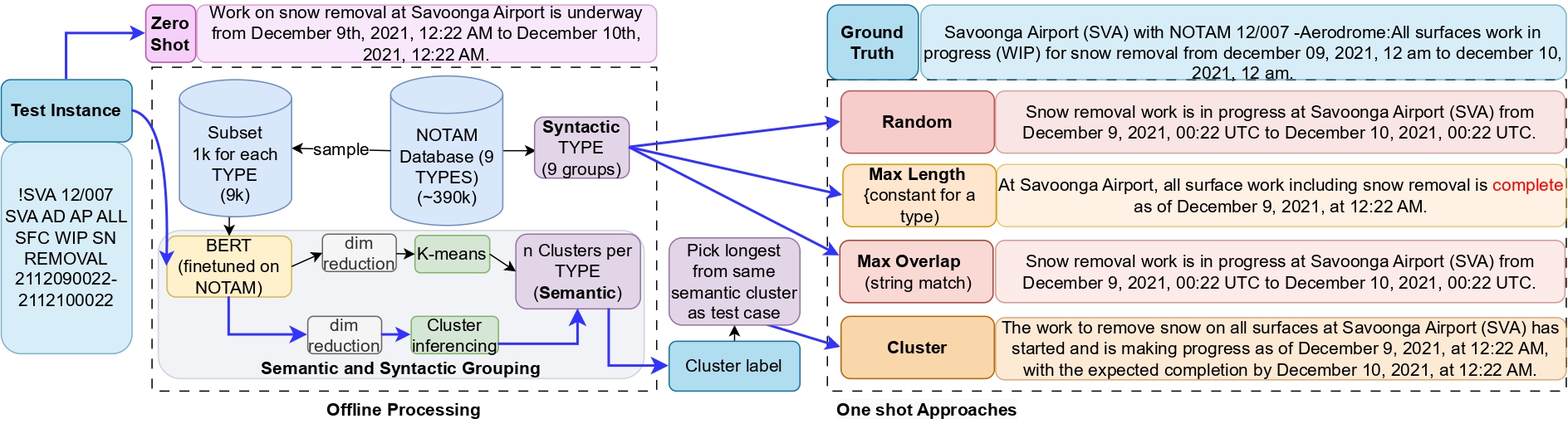
Semantics-aware prompting for translating NOtices To AirMen
Findings of the Association for Computational Linguistics: ACL 2025 (May 2025)
A NOTAM or NOtice To AirMen is a crucial notice for different aviation stakeholders, particularly flight crews. It delivers essential notifications about abnormal conditions of Aviation System components such as changes to facilities, hazards, service, procedure that are not known far enough in advance to be publicized through other means. NOTAM messages are short, contain acronyms, and look cryptic in most of the cases. Writing and understanding these messages put heavy cognitive load on its end users. In this work, we take up the task of translating NOTAMs into English natural language using LLMs. Since NOTAMs do not adhere to English grammar rules and have their own decoding rules, large language models (LLMs) cannot translate them without effective prompting. In this paper, we develop a framework to come up with effective prompts to achieve the translations. Our approach uses context-aware semantic prompting techniques, paired with domain-specific rules, to improve the accuracy and clarity of translations. The framework is evaluated using comprehensive experiments (6 LLMs of varying sizes, and with 5 different prompting setups for each) and eight evaluation metrics measuring different aspects of the translation. The results demonstrate that our methodology can produce clear translations that accurately convey the information contained in NOTAMs.

NLIP at BEA2025 Shared Task: Evaluation of Pedagogical Ability of AI Tutors
BEA Shared Task, SIGEDU, ACL 2025 (May 2025)
This paper presents our system entry in the Building Educational Applications (BEA) 2025 Shared Task on Pedagogical Ability Assessment of AI-powered Tutors. The task evaluates multiple dimensions of AI tutor responses within student-teacher educational dialogues, including mistake identification, mistake location, providing guidance, and actionability. Our approach leverages transformer-based models (Vaswani et al., 2017), especially DeBERTa and RoBERTa, and incorporates ordinal regression, threshold tuning, oversampling, and multi-task learning. Our best-performing systems are capable of assessing tutor response quality across all tracks. This highlights the effectiveness of tailored transformer architectures and pedagogically motivated training strategies for AI tutor evaluation.

Aerial Mirage: Unmasking Hallucinations in Large Vision Language Models
2025 IEEE/CVF Winter Conference on Applications of Computer Vision (WACV) (April 2025)
Drones excel at capturing aerial-view images, especially in human unreachable areas. Automatically interpreting and describing these images enables decision-making easier without the need to review the images extensively. Traditional image captioning models struggle with aerial imagery due to diverse orientations, perspectives, and unclear objects. Integrating the capabilities of Large Vision Language Models (LVLMs) with drone images can improve description utility, benefiting strategic missions like surveillance, search and rescue, etc. However, the lack of image-caption datasets for drone imagery poses a significant challenge for training and evaluating drone image captioning. To address this gap, we contribute the first Aerial-view Image Captioning dataset (AeroCaps), containing four captions per image. Another major hurdle for the task is the hallucinatory nature of LVLMs. To this end, we perform the first extensive analysis of hallucinations on aerial imagery by two SOTA LVLMs - LLaVA and InstructBLIP on our proposed dataset and VisDrone. We explore the reasons behind such hallucinations. We release the LVLM-generated image captions along with our hallucination-labelled annotations as the Labelled Illusion Dataset (LID) for further research. Additionally, we review how effective advanced LLMs like GPT-4 are in evaluating the degree of hallucinations made by other LVLMs like LLaVA.
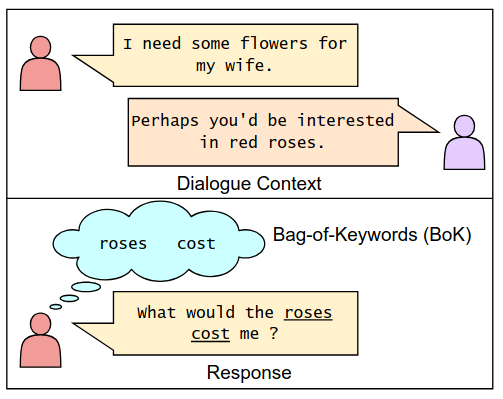
BoK: Introducing Bag-of-Keywords Loss for Interpretable Dialogue Response Generation
25th Annual Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL 2024) (September 2024)
The standard language modeling (LM) loss by itself has been shown to be inadequate for effective dialogue modeling. As a result, various training approaches, such as auxiliary loss functions and leveraging human feedback, are being adopted to enrich open-domain dialogue systems. One such auxiliary loss function is Bag-of-Words (BoW) loss, defined as the cross-entropy loss for predicting all the words/tokens of the next utterance. In this work, we propose a novel auxiliary loss named Bag-of-Keywords (BoK) loss to capture the central thought of the response through keyword prediction and leverage it to enhance the generation of meaningful and interpretable responses in open-domain dialogue systems. BoK loss upgrades the BoW loss by predicting only the keywords or critical words/tokens of the next utterance, intending to estimate the core idea rather than the entire response. We incorporate BoK loss in both encoder-decoder (T5) and decoder-only (DialoGPT) architecture and train the models to minimize the weighted sum of BoK and LM (BoK-LM) loss. We perform our experiments on two popular open-domain dialogue datasets, DailyDialog and Persona-Chat. We show that the inclusion of BoK loss improves the dialogue generation of backbone models while also enabling post-hoc interpretability. We also study the effectiveness of BoK-LM loss as a reference-free metric and observe comparable performance to the state-of-the-art metrics on various dialogue evaluation datasets.
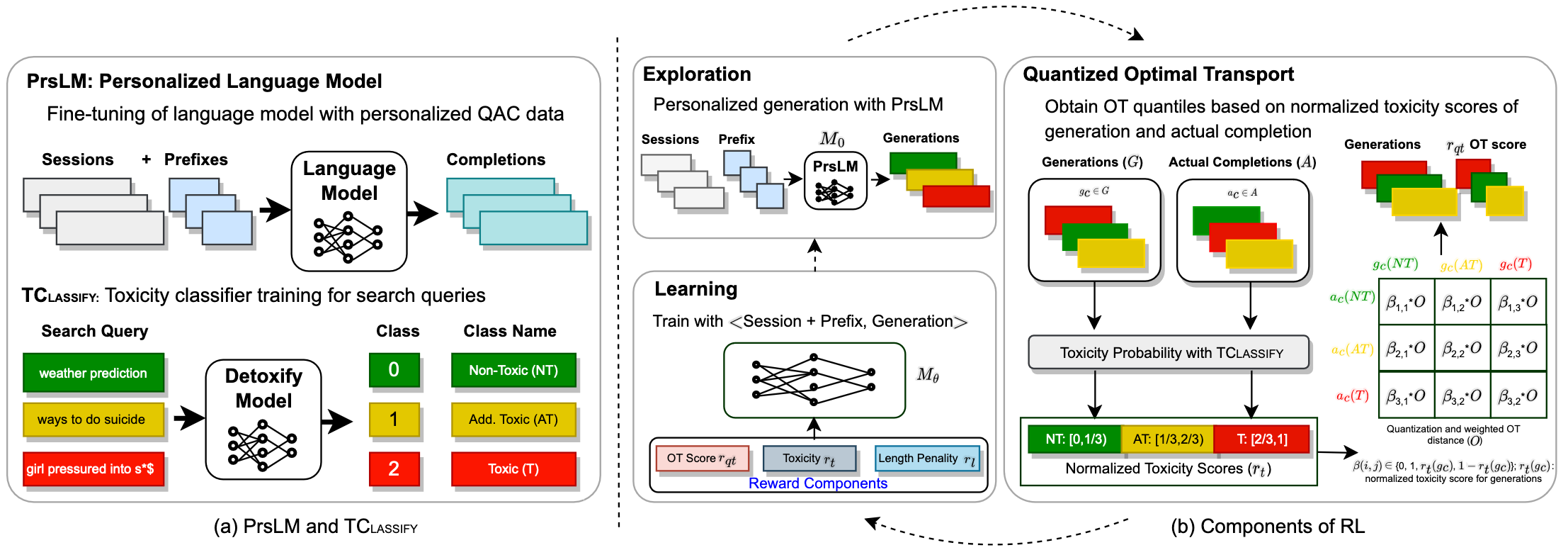
DAC: Quantized Optimal Transport Reward-based Reinforcement Learning Approach to Detoxify Query Auto-Completion
47th International ACM SIGIR Conference on Research and Development in Information Retrieval (SIGIR 2024) (July 2024)
Modern Query Auto-Completion (QAC) systems utilize natural language generation (NLG) using large language models (LLM) to achieve remarkable performance. However, these systems are prone to generating biased and toxic completions due to inherent learning biases. Existing detoxification approaches exhibit two key limitations: (1) They primarily focus on mitigating toxicity for grammatically well-formed long sentences but struggle to adapt to the QAC task, where queries are short and structurally different (include spelling errors, do not follow grammatical rules and have relatively flexible word order). (2) These approaches often view detoxification through a binary lens where all text labeled as toxic is undesirable and non-toxic is considered desirable. To address these limitations, we propose DAC, an intuitive and efficient reinforcement learning-based model to detoxify QAC. With DAC, we introduce an additional perspective of considering the third query class of addressable toxicity. These queries can encompass implicit toxicity, subjective toxicity, or non-toxic queries containing toxic words. We incorporate this three-class query behavior perspective into the proposed model through quantized optimal transport to learn distinctions and generate truly non-toxic completions. We evaluate toxicity levels in the generated completions by DAC across two real-world QAC datasets (Bing and AOL) using two classifiers: a publicly available generic classifier (Detoxify) and a search query-specific classifier, which we develop (TClassify). we find that DAC consistently outperforms all existing baselines on the Bing dataset and achieves competitive performance on the AOL dataset for query detoxification. % providing high quality and low toxicity. We make the code and models publicly available.
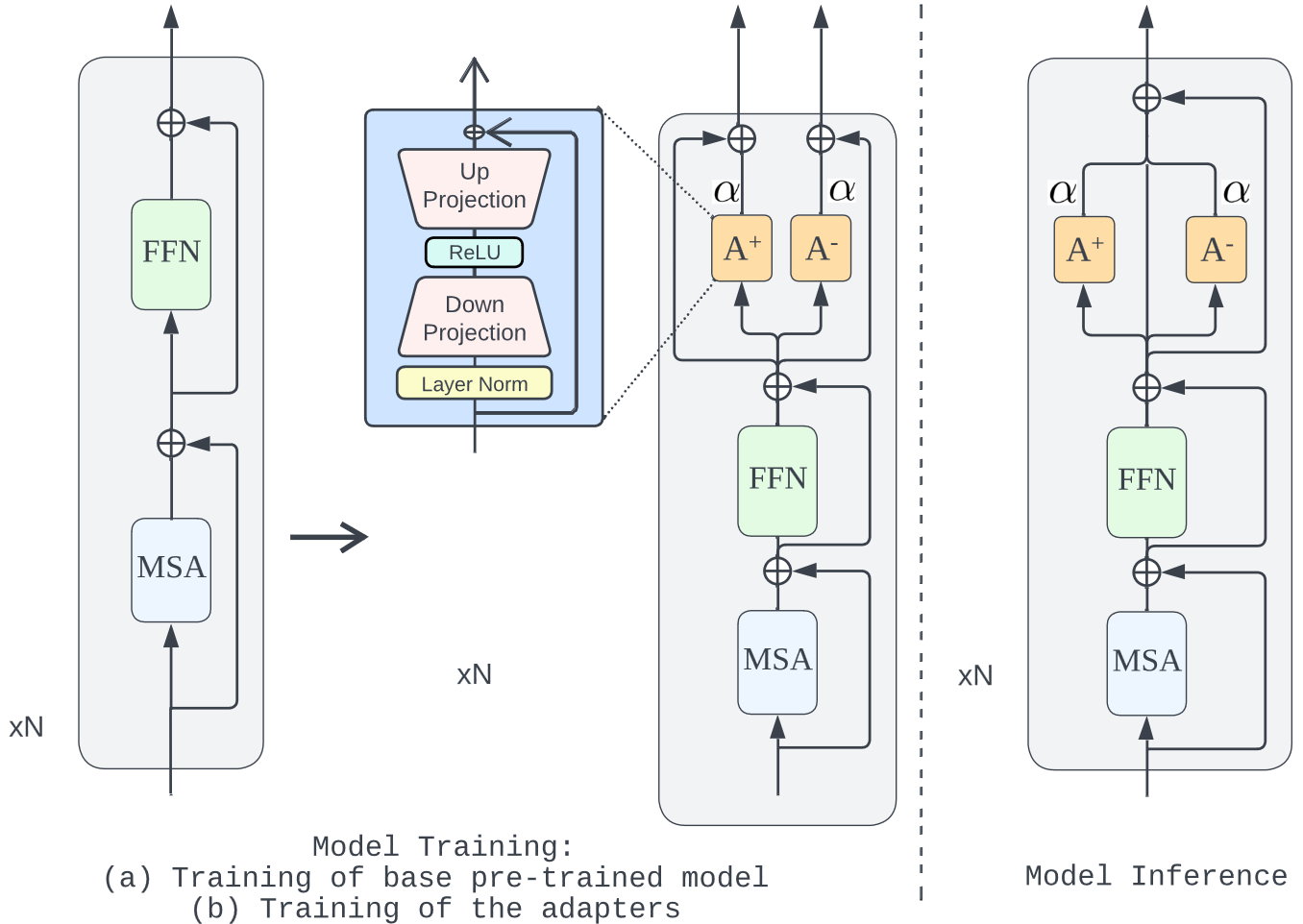
DQAC: Detoxifying Query Auto-Completion with Adapters
28th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2024) (May 2024)
Recent Query Auto-completion (QAC) systems leverage natural language generation or pre-trained language models (PLMs) to demonstrate remarkable performance. However, these systems also suffer from biased and toxic completions. Efforts have been made to address language detoxification within PLMs using controllable text generation (CTG) techniques, involving training with non-toxic data and employing decoding time approaches. As the completions for QAC systems are usually short, these existing CTG methods based on decoding and training are not directly transferable. Towards these concerns, we propose the first public QAC detoxification model, Detoxifying Query Auto-Completion (or DQAC), which utilizes adapters in a CTG framework. DQAC operates on latent representations with no additional overhead. It leverages two adapters for toxic and non-toxic cases. During inference, we fuse these representations in a controlled manner that guides the generation of query completions towards non-toxicity. We evaluate toxicity levels in the generated completions across two real-world datasets using two classifiers: a publicly available (Detoxify) and a search query-specific classifier which we develop (QDetoxify). DQAC consistently outperforms all existing baselines and emerges as a state-of-the-art model providing high quality and low toxicity. We make the code publicly available at https://shorturl.at/zJ024
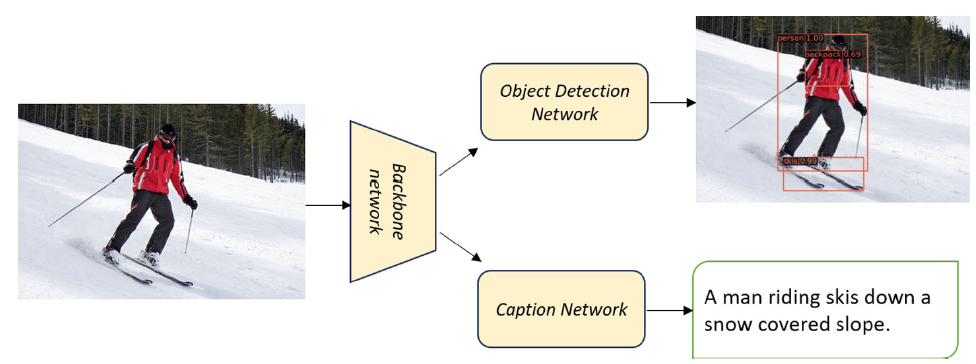
Transformer Based Multitask Learning for Image Captioning and Object Detection
28th Pacific-Asia Conference on Knowledge Discovery and Data Mining (PAKDD 2024) (May 2024)
In several real-world scenarios like autonomous navigation and mobility, to obtain a better visual understanding of the surroundings, image captioning and object detection play a crucial role. This work introduces a novel multitask learning framework that combines image captioning and object detection intoa joint model. We propose TICOD, Transformer-based Image Captioning andObject Detection model for jointly training both tasks by combining the losses obtained from image captioning and object detection networks. By leveraging joint training, the model benefits from the complementary information shared AQ1between the two tasks, leading to improved performance for image captioning.Our approach utilizes a transformer-based architecture that enables end-to-end AQ2network integration for image captioning and object detection and performs bothtasks jointly. We evaluate the effectiveness of our approach through comprehensive experiments on the MS-COCO dataset. Our model outperforms the baselinesfrom image captioning literature by achieving a 3.65% improvement in BERTScore.
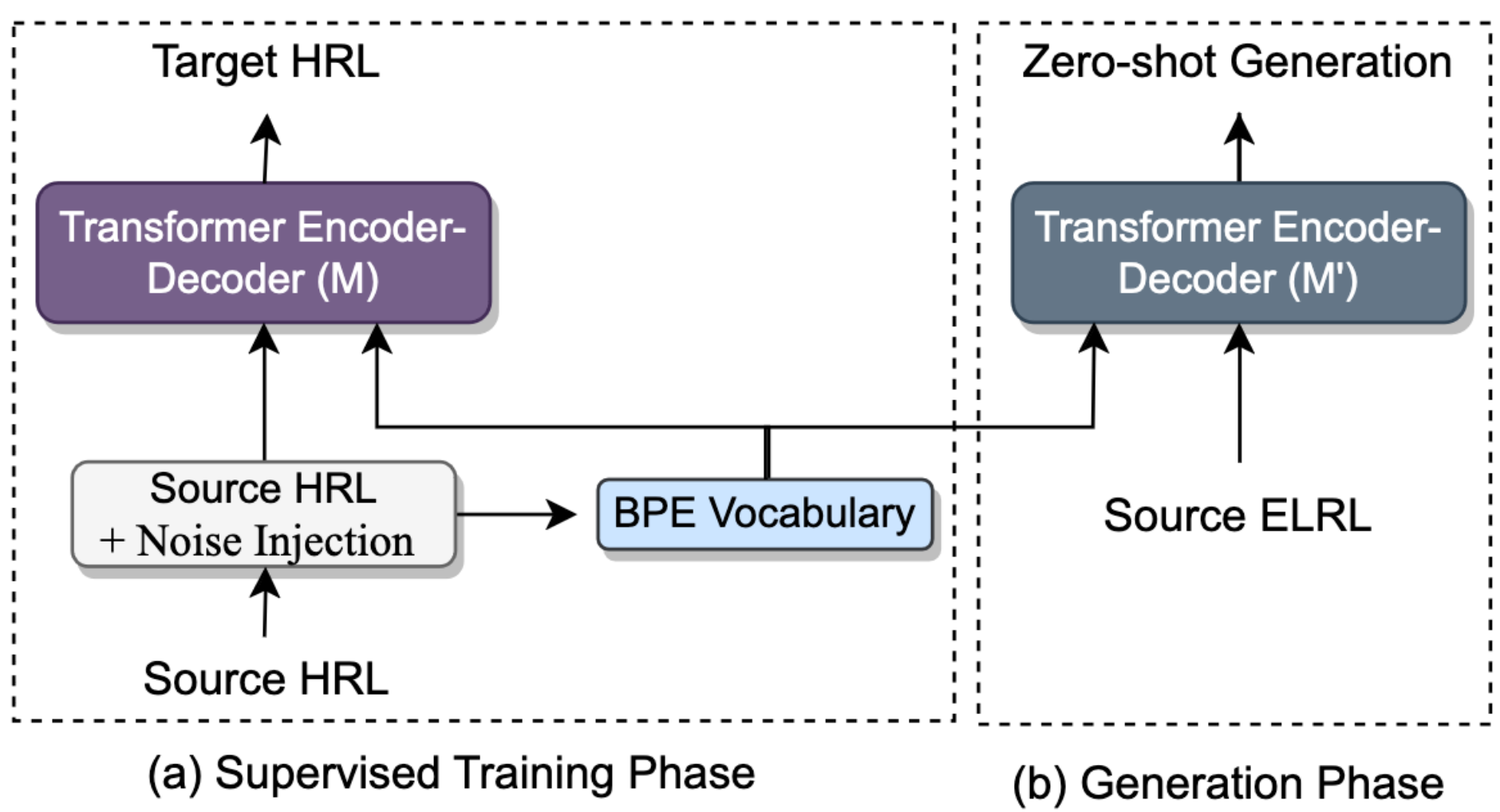
CharSpan: Utilizing Lexical Similarity to Enable Zero-Shot Machine Translation for Extremely Low-resource Languages
18th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2024) (March 2024)
We address the task of machine translation(MT) from extremely low-resource language(ELRL) to English by leveraging cross-lingualtransfer from closely-related high-resourcelanguage (HRL). The development of an MTsystem for ELRL is challenging because theselanguages typically lack parallel corpora andmonolingual corpora, and their representationsare absent from large multilingual languagemodels. Many ELRLs share lexical similaritieswith some HRLs, which presents a novelmodeling opportunity. However, existingsubword-based neural MT models do notexplicitly harness this lexical similarity, as theyonly implicitly align HRL and ELRL latentembedding space. To overcome this limitation,we propose a novel, CHARSPAN, approachbased on character-span noise augmentationinto the training data of HRL. This serves asa regularization technique, making the modelmore robust to lexical divergences betweenthe HRL and ELRL, thus facilitating effectivecross-lingual transfer. Our method significantlyoutperformed strong baselines in zero-shotsettings on closely related HRL and ELRL pairsfrom three diverse language families, emergingas the state-of-the-art model for ELRLs.
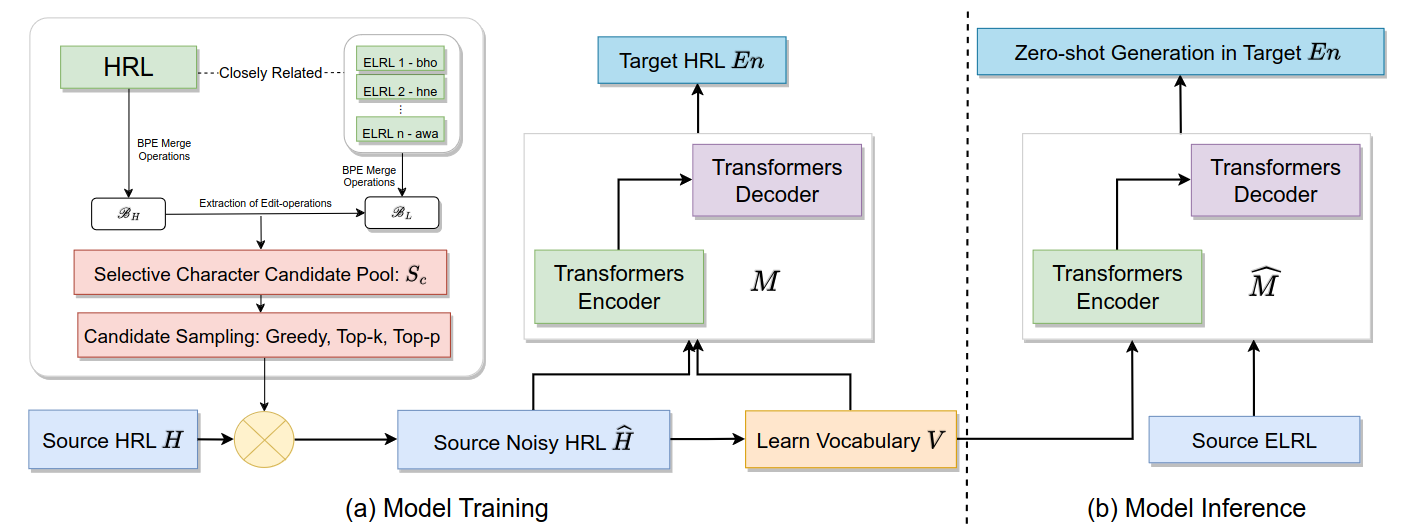
SelectNoise: Unsupervised Noise Injection to Enable Zero-shot Machine Translation for Extremely Low-resource languages
(October 2023)
In this work, we focus on the task of machine translation (MT) from extremely low-resource language (ELRLs) to English. The unavailability of parallel data, lack of representation from large multilingual pre-trained models, and limited monolingual data hinder the development of MT systems for ELRLs. However, many ELRLs often share lexical similarities with high-resource languages (HRLs) due to factors such as dialectical variations, geographical proximity, and language structure. We utilize this property to improve cross-lingual signals from closely related HRL to enable MT for ELRLs. Specifically, we propose a novel unsupervised approach, SelectNoise, based on selective candidate extraction and noise injection to generate noisy HRLs training data. The noise injection acts as a regularizer, and the model trained with noisy data learns to handle lexical variations such as spelling, grammar, and vocabulary changes, leading to improved cross-lingual transfer to ELRLs. The selective candidates are extracted using BPE merge operations and edit operations, and noise injection is performed using greedy, top-p, and top-k sampling strategies. We evaluate the proposed model on 12 ELRLs from the FLORES-200 benchmark in a zero-shot setting across two language families. The proposed model outperformed all the strong baselines, demonstrating its efficacy. It has comparable performance with the supervised noise injection model.
Towards Low-resource Language Generation with Limited Supervision
Proceedings of the Big Picture Workshop, Association for Computational Linguistics (October 2023)
We present a research narrative aimed at enabling language technology for multiple natural language generation (NLG) tasks in low-resource languages (LRLs). With approximately 7,000 languages spoken globally, many lack the resources required for model training. NLG applications for LRLs present two additional key challenges: (i) The training is more pronounced, and (ii) Zero-shot modeling is a viable research direction for scalability; however, generating zero-shot well-formed text in target LRLs is challenging. Addressing these concerns, this narrative introduces three promising research explorations that serve as a step toward enabling language technology for many LRLs. These approaches make effective use of transfer learning and limited supervision techniques for modeling. Evaluations were conducted mostly in the zero-shot setting, enabling scalability. This research narrative is an ongoing doctoral thesis.

Trie-NLG: Trie Context Augmentation to Improve Personalized Query Auto-Completion for Short and Unseen Prefixes
Journal track at European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML-PKDD 2023) (July 2023)
Query auto-completion (QAC) aims at suggesting plausible completions for a given query prefix. Traditionally, QAC systems have leveraged tries curated from historical query logs to suggest most popular completions. In this context, there are two specific scenarios that are difficult to handle for any QAC system: short prefixes (which are inherently ambiguous) and unseen prefixes. Recently, personalized Natural Language Generation (NLG) models have been proposed to leverage previous session queries as context for addressing these two challenges. However, such NLG models suffer from two drawbacks: (1) some of the previous session queries could be noisy and irrelevant to the user intent for the current prefix, and (2) NLG models cannot directly incorporate historical query popularity. This motivates us to propose a novel NLG model for QAC, Trie-NLG, which jointly leverages popularity signals from trie and personalization signals from previous session queries. We train the Trie-NLG model by augmenting the prefix with rich context comprising of recent session queries and top trie completions. This simple modeling approach overcomes the limitations of trie-based and NLG-based approaches and leads to state-of-the-art performance. We evaluate the Trie-NLG model using two large QAC datasets. On average, our model achieves huge ∼57% and ∼14% boost in MRR over the popular trie-based lookup and the strong BART-based baseline methods, respectively.
On Text Style Transfer via Style-Aware Masked Language Models
16th International Natural Language Generation Conference (INLG 2023) (July 2023)
Text Style Transfer (TST) involves transforming a source sentence with a given style label to an output with another target style meanwhile preserving content and fluency. We look at a fill-in-the-blanks approach (also referred to as prototype editing), where the source sentence is stripped off all style-containing words and filled in with suitable words. This closely resembles a Masked Language Model (MLM) objective, with the added initial step of masking only relevant style words rather than BERT's random masking. We show this simple MLM, trained to reconstruct style-masked sentences back into their original style, can even transfer style by making this MLM Style-Aware. This simply involves appending the source sentence with a target style special token. The Style-Aware MLM (SA-MLM), now also accounts for the direction of style transfer and enables style transfer by simply manipulating these special tokens. To learn this n-word to n-word style reconstruction task, we use a single transformer encoder block with 8 heads, 2 layers and no auto-regressive decoder, making it non-generational. We empirically show that this lightweight encoder trained on a simple reconstruction task compares with elaborately engineered state-of-the-art TST models for even complex styles like Discourse or flow of logic, i.e. Contradiction to Entailment and vice-versa. Additionally, we introduce a more accurate attention-based style-masking step and a novel attention-surplus method to determine the position of masks from any arbitrary attribution model in O(1) time. Finally, we show that the SA-MLM arises naturally by considering a probabilistic framework for style transfer.

Dial-M: A Masking-based Framework for Dialogue Evaluation
24th Meeting of the Special Interest Group on Discourse and Dialogue (SIGDIAL 2023)
Nominated for Best Paper Award (July 2023)
In dialogue systems, automatically evaluating machine-generated responses is critical and challenging. Despite the tremendous progress in dialogue generation research, its evaluation heavily depends on human judgments. The standard word-overlapping based evaluation metrics are ineffective for dialogues. As a result, most of the recently proposed metrics are model-based and reference-free, which learn to score different aspects of a conversation. However, understanding each aspect requires a separate model, which makes them computationally expensive. To this end, we propose Dial-M, a Masking-based reference-free framework for Dialogue evaluation. The main idea is to mask the keywords of the current utterance and predict them, given the dialogue history and various conditions (like knowledge, persona, etc.), thereby making the evaluation framework simple and easily extensible for multiple datasets. Regardless of its simplicity, Dial-M achieves comparable performance to state-of-the-art metrics on several dialogue evaluation datasets. We also discuss the interpretability of our proposed metric along with error analysis.
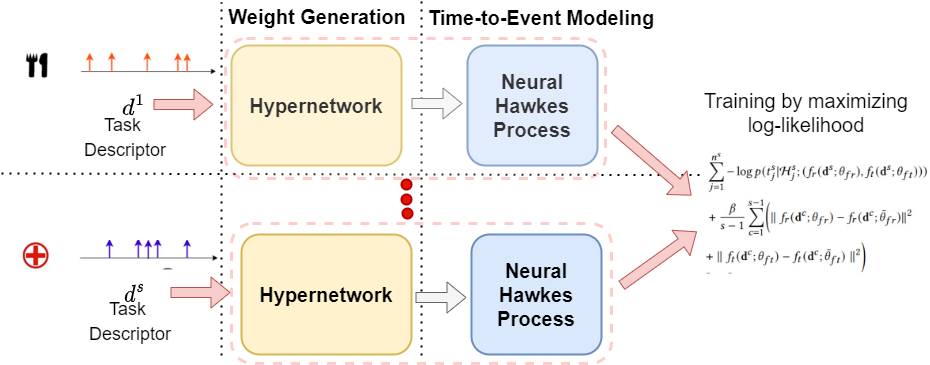
Time-to-Event Modeling with Hypernetwork based Hawkes Process
29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (SIGKDD 2023) (August 2023)
Many real-world applications are associated with collection of events with timestamps, known as time-to-event data. Earthquake occurrences, social networks, and user activity logs can be represented as a sequence of discrete events observed in continuous time. Temporal point process serves as an essential tool for modeling such time-to-event data in continuous time space. Despite having massive amounts of event sequence data from various domains like social media, healthcare etc., real world application of temporal point process faces two major challenges: 1) it is not generalizable to predict events from unseen event sequences in dynamic environment 2) they are not capable of thriving in continually evolving environment with minimal supervision while retaining previously learnt knowledge. To tackle these issues, we propose HyperHawkes, a hypernetwork based temporal point process framework which is capable of modeling time of event occurrence for unseen sequences and consequently, zero-shot learning for time-to-event modeling. We also develop a hypernetwork based continually learning temporal point process for continuous modeling of time-to-event sequences with minimal forgetting. HyperHawkes augments the temporal point process with zero-shot modeling and continual learning capabilities. We demonstrate the application of the proposed framework through our experiments on real-world datasets. Our results show the efficacy of the proposed approach in terms of predicting future events under zero-shot regime for unseen event sequences. We also show that the proposed model is able to learn the time-to-event sequences continually while retaining information from previous event sequences, mitigating catastrophic forgetting in neural temporal point process.
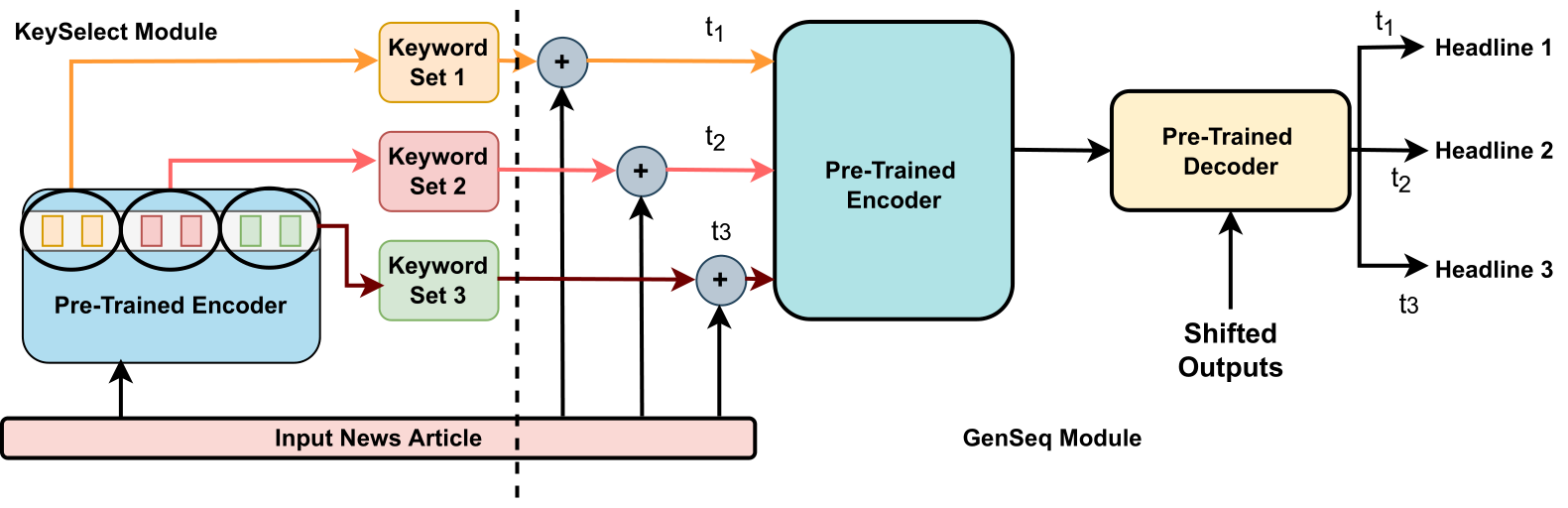
DivHSK: Diverse Headline Generation using Self-Attention based Keyword Selection
61st Annual Meeting of the Association for Computational Linguistics (ACL 2023) (July 2023)
Diverse headline generation is an NLP task where given a news article, the goal is to generate multiple headlines that are true to the content of the article, but are different among themselves. This task aims to exhibit and exploit semantically similar one-to-many relationships between a source news article and multiple target headlines. Towards this, we propose a novel model called DIVHSK. It has two components: KEYSELECT for selecting the important keywords, and SEQGEN, for finally generating the multiple diverse headlines. In KEYSELECT, we cluster the self-attention heads of the last layer of the pre-trained encoder and select the mostattentive theme and general keywords from the source article. Then, cluster-specific keyword sets guide the SEQGEN, a pre-trained encoderdecoder model, to generate diverse yet semantically similar headlines. The proposed model consistently outperformed existing literature and our strong baselines and emerged as a stateof-the-art model. Additionally, We have also created a high-quality multi-reference headline dataset from news articles

Towards Improvement of Grounded Cross-Lingual Natural Language Inference with VisioTextual Attention
Natural Language Processing (Elsevier) (July 2023)
Natural Language Inference (NLI) has been one of the fundamental tasks in Natural Language Processing (NLP). Recognizing Textual Entailment (RTE) between the two pieces of text is a crucial problem. It adds further challenges when it involves two languages, i.e., in the cross-lingual scenario. In this paper, we propose VisioTextual-Attention (VTA) — an effective visual–textual coattention mechanism for multi-modal crosslingual NLI. Through our research, we show that instead of using only linguistic input features, introducing visual features supporting the textual inputs improves the performance of NLI models if an effective cross-modal attention mechanism is carefully constructed. We perform several experiments on a standard cross-lingual textual entailment dataset in Hindi–English language pairs and show that the addition of visual information to the dataset along with our proposed VisioTextual Attention (VTA) enhances performance and surpasses the current state-of-the-art by 4.5%. Through monolingual experiments, we also show that the proposed VTA mechanism surpasses monolingual state-of-the-art by a margin of 2.89%. We argue that our VTA mechanism is model agnostic and can be used with other deep learning-based architectures for grounded cross-lingual NLI.

GNoM: Graph Neural Network Enhanced Language Models for Disaster Related Multilingual Text Classification
WebSci 2022: 14th ACM Web Science Conference 2022 (June 2022)
Online social media works as a source of various valuable and actionable information during disasters. These information might be available in multiple languages due to the nature of user generated content. An effective system to automatically identify and categorize these actionable information should be capable to handle multiple languages and under limited supervision. However, existing works mostly focus on English language only with the assumption that sufficient labeled data is available. To overcome these challenges, we propose a multilingual disaster related text classification system which is capable to work undervmonolingual, cross-lingual and multilingual lingual scenarios and under limited supervision. Our end-to-end trainable framework combines the versatility of graph neural networks, by applying over the corpus, with the power of transformer based large language models, over examples, with the help of cross-attention between the two. We evaluate our framework over total nine English, Non-English and monolingual datasets invmonolingual, cross-lingual and multilingual lingual classification scenarios. Our framework outperforms state-of-the-art models in disaster domain and multilingual BERT baseline in terms of Weighted F1 score. We also show the generalizability of the proposed model under limited supervision.
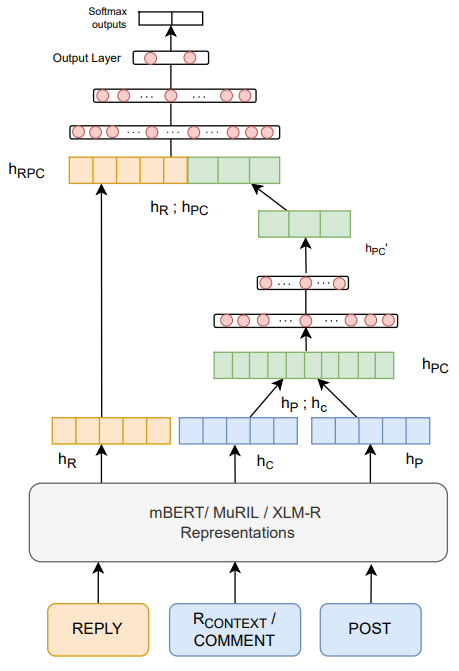
Hostility Detection in Online Hindi-English Code-Mixed Conversations
WebSci 2022: 14th ACM Web Science Conference 2022 (June 2022)
With the rise in accessibility and popularity of various social media platforms, people have started expressing and communicating their ideas, opinions, and interests online. While these platforms are active sources of entertainment and idea-sharing, they also attract hostile and offensive content equally. Identification of hostile posts is an essential and challenging task. In particular, Hindi-English Code-Mixed online posts of conversational nature (which have a hierarchy of posts, comments, and replies) have escalated the challenges. There are two major challenges: (1) the complex structure of Code-Mixed text and (2) filtering the relevant previous context for a given utterance. To overcome these challenges, in this paper, we propose a novel hierarchical neural network architecture to identify hostile posts/comments/replies in online Hindi-English Code-Mixed conversations. We leverage large multilingual pre-trained (mLPT) models like mBERT, XLMR, and MuRIL. The mLPT models provide a rich representation of code-mix text and hierarchical modeling leads to a natural abstraction and selection of the relevant context. The propose model consistently outperformed all the baselines and emerged as a state-of-the-art performing model. We conducted multiple analyses and ablation studies to prove the robustness of the proposed model.
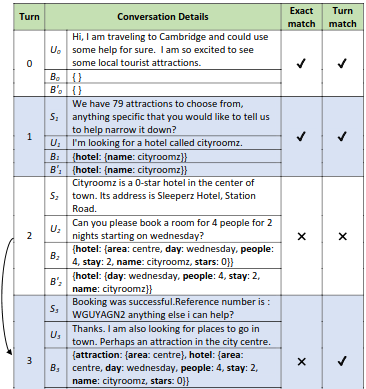
Towards Fair Evaluation of Dialogue State Tracking by Flexible Incorporation of Turn-level Performances
Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers) (May 2022)
Dialogue State Tracking (DST) is primarily evaluated using Joint Goal Accuracy (JGA) defined as the fraction of turns where the ground-truth dialogue state exactly matches the prediction. Generally in DST, the dialogue state or belief state for a given turn contain all the intents shown by the user till that turn. Due to this cumulative nature of the belief state, it is difficult to get a correct prediction once a misprediction has occurred. Thus, although being a useful metric, it can be harsh at times and underestimate the true potential of a DST model. Moreover, an improvement in JGA can sometimes decrease the performance of turn-level or non-cumulative belief state prediction due to inconsistency in annotations. So, using JGA as the only metric for model selection may not be ideal for all scenarios. In this work, we discuss various evaluation metrics used for DST along with their shortcomings. To address the existing issues, we propose a new evaluation metric named Flexible Goal Accuracy (FGA). FGA is a generalized version of JGA. But unlike JGA, it tries to give penalized rewards to mispredictions that are locally correct i.e. the root cause of the error is an earlier turn. By doing so, FGA considers the performance of both cumulative and turn-level prediction flexibly and provides a better insight than the existing metrics. We also show that FGA is a better discriminator of DST model performance.
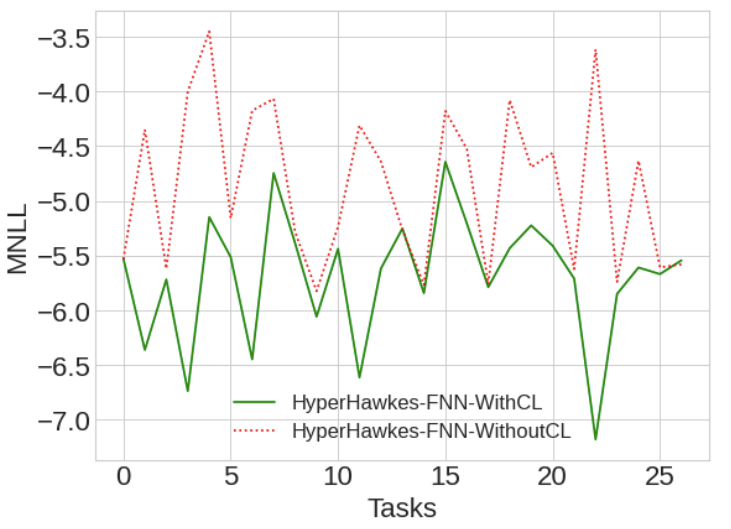
Continual Learning for Time-to-Event Modeling
Continual Lifelong Learning Workshop at ACML 2022 (October 2022)
Temporal point process serves as an essential tool for modeling time-to-event data in continuous time space. Despite having massive amounts of event sequence data from various domains like social media, healthcare etc., real world application of temporal point process are not capable of thriving in continually evolving environment with minimal supervision while retaining previously learnt knowledge. To tackle this, we propose HyperHawkes, a hypernetwork based continually learning temporal point process for continuous modeling of time-to-event sequences with minimal forgetting. We demonstrate the application of the proposed framework through our experiments on two real-world datasets.
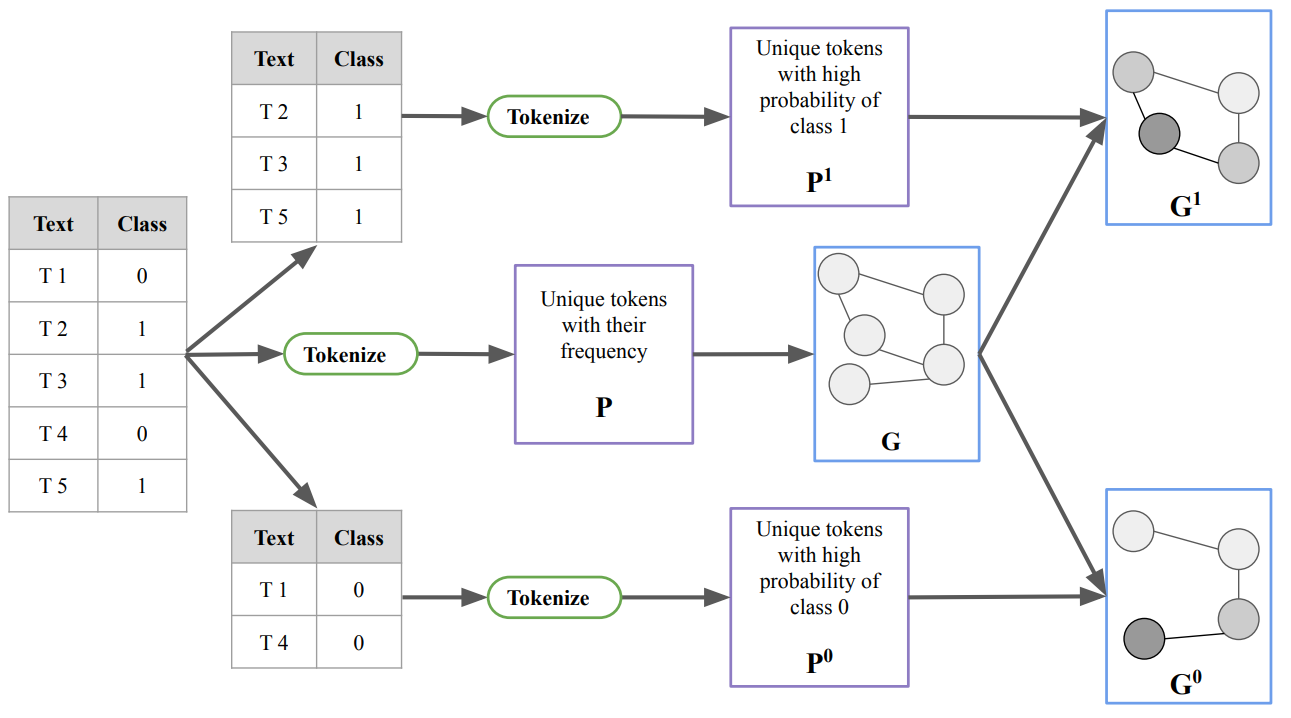
Supervised Graph Contrastive Pretraining for Text Classification
In Proceedings of ACM SAC Conference (SAC 2022) (December 2022)
Contrastive pretraining techniques for text classification has been largely studied in an unsupervised setting. However, oftentimes labeled data from related tasks which share label semantics with current task is available. We hypothesize that using this labeled data effectively can lead to better generalization on current task. In this paper, we propose a novel way to effectively utilize labeled data from related tasks with a graph based supervised contrastive learning approach. We formulate a token-graph by extrapolating the supervised information from examples to tokens. Our formulation results in an embedding space where tokens with high/low probability of belonging to same class are near/further-away from one another. We also develop detailed theoretical insights which serve as a motivation for our method. In our experiments with 13 datasets, we show our method outperforms pretraining schemes by 2.5% and also example-level contrastive learning based formulation by 1.8% on average. In addition, we show cross-domain effectiveness of our method in a zero-shot setting by 3.91% on average. Lastly, we also demonstrate our method can be used as a noisy teacher in a knowledge distillation setting to significantly improve performance of transformer based models in low labeled data regime by 4.57% on average.
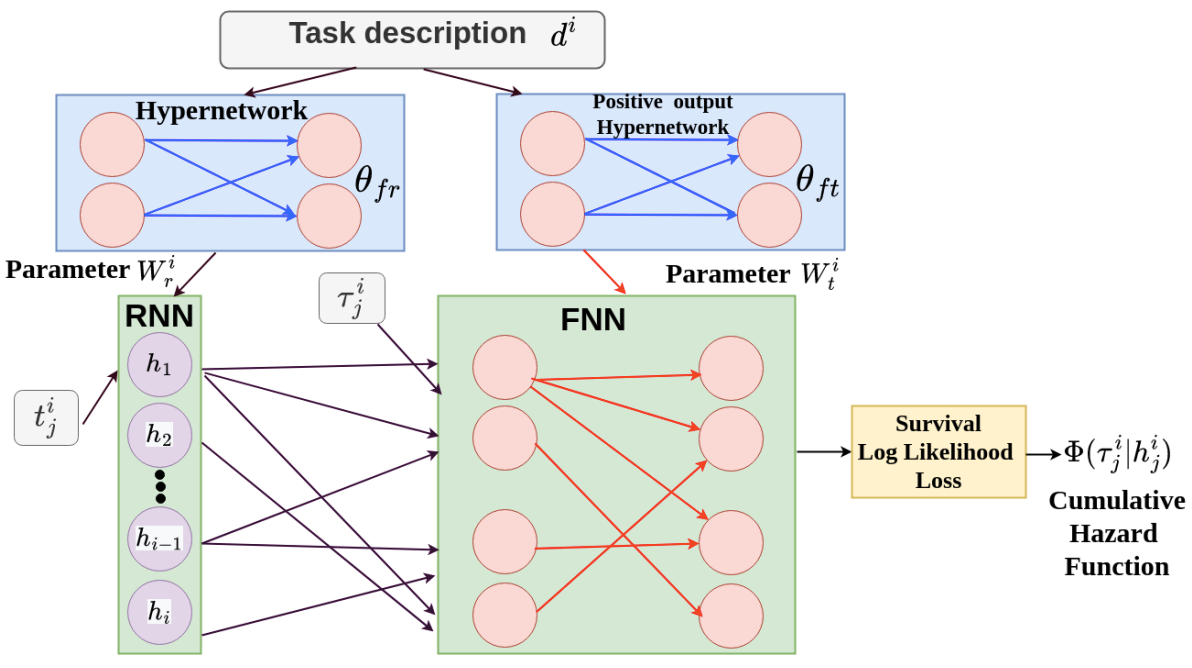
HyperHawkes: Hypernetwork based Neural Temporal Point Process
arXiv preprint arXiv:2205.02309 (August 2022)
Temporal point process serves as an essential tool for modeling time-to-event data in continuous time space. Despite having massive amounts of event sequence data from various domains like social media, healthcare etc., real world application of temporal point process faces two major challenges: 1) it is not generalizable to predict events from unseen sequences in dynamic environment 2) they are not capable of thriving in continually evolving environment with minimal supervision while retaining previously learnt knowledge. To tackle these issues, we propose extit{HyperHawkes}, a hypernetwork based temporal point process framework which is capable of modeling time of occurrence of events for unseen sequences. Thereby, we solve the problem of zero-shot learning for time-to-event modeling. We also develop a hypernetwork based continually learning temporal point process for continuous modeling of time-to-event sequences with minimal forgetting. In this way, extit{HyperHawkes} augments the temporal point process with zero-shot modeling and continual learning capabilities. We demonstrate the application of the proposed framework through our experiments on two real-world datasets. Our results show the efficacy of the proposed approach in terms of predicting future events under zero-shot regime for unseen event sequences. We also show that the proposed model is able to predict sequences continually while retaining information from previous event sequences, hence mitigating catastrophic forgetting for time-to-event data.
Effective utilization of labeled data from related tasks using graph contrastive pretraining: application to disaster related text classification
SAC '22: Proceedings of the 37th ACM/SIGAPP Symposium on Applied Computing (June 2022)
Contrastive pretraining techniques for text classification has been largely studied in an unsupervised setting. However, oftentimes labeled data from related past datasets which share label semantics with current task is available. We hypothesize that using this labeled data effectively can lead to better generalization on current task. In this paper, we propose a novel way to effectively utilize labeled data from related tasks with a graph based supervised contrastive learning approach. We formulate a token-graph by extrapolating the supervised information from examples to tokens. Our experiments with 8 disaster datasets show our method outperforms baselines and also example-level contrastive learning based formulation. In addition, we show cross-domain effectiveness of our method in a zero-shot setting.
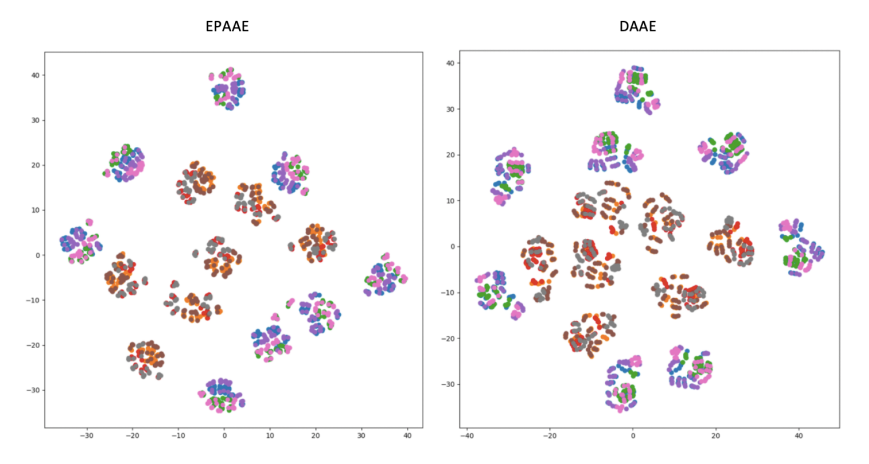
Towards Robust and Semantically Organised Latent Representations for Unsupervised Text Style Transfer
Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (May 2022)
Recent studies show that auto-encoder based approaches successfully perform language generation, smooth sentence interpolation, and style transfer over unseen attributes using unlabelled datasets in a zero-shot manner. The latent space geometry of such models is organised well enough to perform on datasets where the style is 'coarse-grained' i.e. a small fraction of words alone in a sentence are enough to determine the overall style label. A recent study uses a discrete token-based perturbation approach to map 'similar' sentences ('similar' defined by low Levenshtein distance/ high word overlap) close by in latent space. This definition of 'similarity' does not look into the underlying nuances of the constituent words while mapping latent space neighbourhoods and therefore fails to recognise sentences with different style-based semantics while mapping latent neighbourhoods. We introduce EPAAEs (Embedding Perturbed Adversarial AutoEncoders) which completes this perturbation model, by adding a finely adjustable noise component on the continuous embeddings space. We empirically show that this (a) produces a better organised latent space that clusters stylistically similar sentences together, (b) performs best on a diverse set of text style transfer tasks than similar denoising-inspired baselines, and (c) is capable of fine-grained control of Style Transfer strength. We also extend the text style transfer tasks to NLI datasets and show that these more complex definitions of style are learned best by EPAAE. To the best of our knowledge, extending style transfer to NLI tasks has not been explored before.
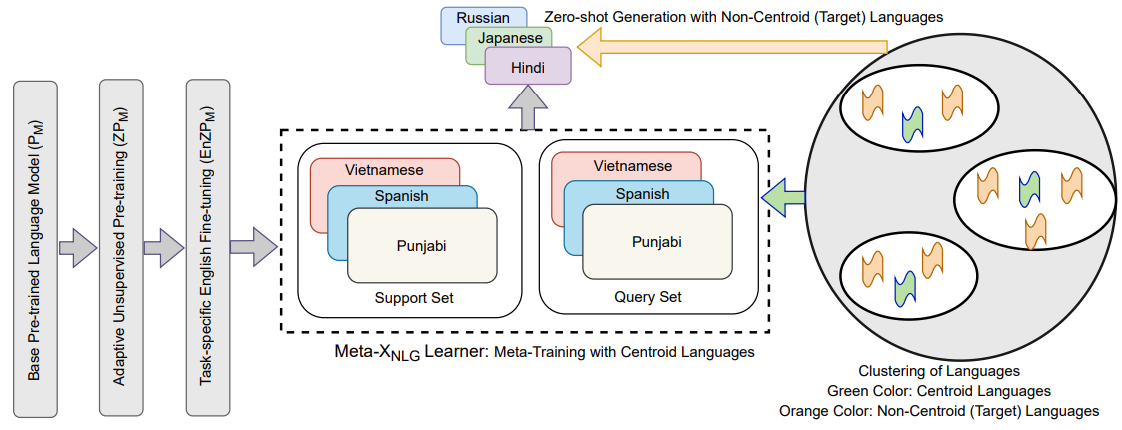
Meta-XNLG: A Meta-Learning Approach Based on Language Clustering for Zero-Shot Cross-Lingual Transfer and Generation
Findings of the Association for Computational Linguistics, ACL 2022 (May 2022)
Recently, the NLP community has witnessed a rapid advancement in multilingual and cross-lingual transfer research where the supervision is transferred from high-resource languages (HRLs) to low-resource languages (LRLs). However, the cross-lingual transfer is not uniform across languages, particularly in the zero-shot setting. Towards this goal, one promising research direction is to learn shareable structures across multiple tasks with limited annotated data. The downstream multilingual applications may benefit from such a learning setup as most of the languages across the globe are low-resource and share some structures with other languages. In this paper, we propose a novel meta-learning framework (called Meta-X$_{NLG}$) to learn shareable structures from typologically diverse languages based on meta-learning and language clustering. This is a step towards uniform cross-lingual transfer for unseen languages. We first cluster the languages based on language representations and identify the centroid language of each cluster. Then, a meta-learning algorithm is trained with all centroid languages and evaluated on the other languages in the zero-shot setting. We demonstrate the effectiveness of this modeling on two NLG tasks (Abstractive Text Summarization and Question Generation), 5 popular datasets and 30 typologically diverse languages. Consistent improvements over strong baselines demonstrate the efficacy of the proposed framework. The careful design of the model makes this end-to-end NLG setup less vulnerable to the accidental translation problem, which is a prominent concern in zero-shot cross-lingual NLG tasks.
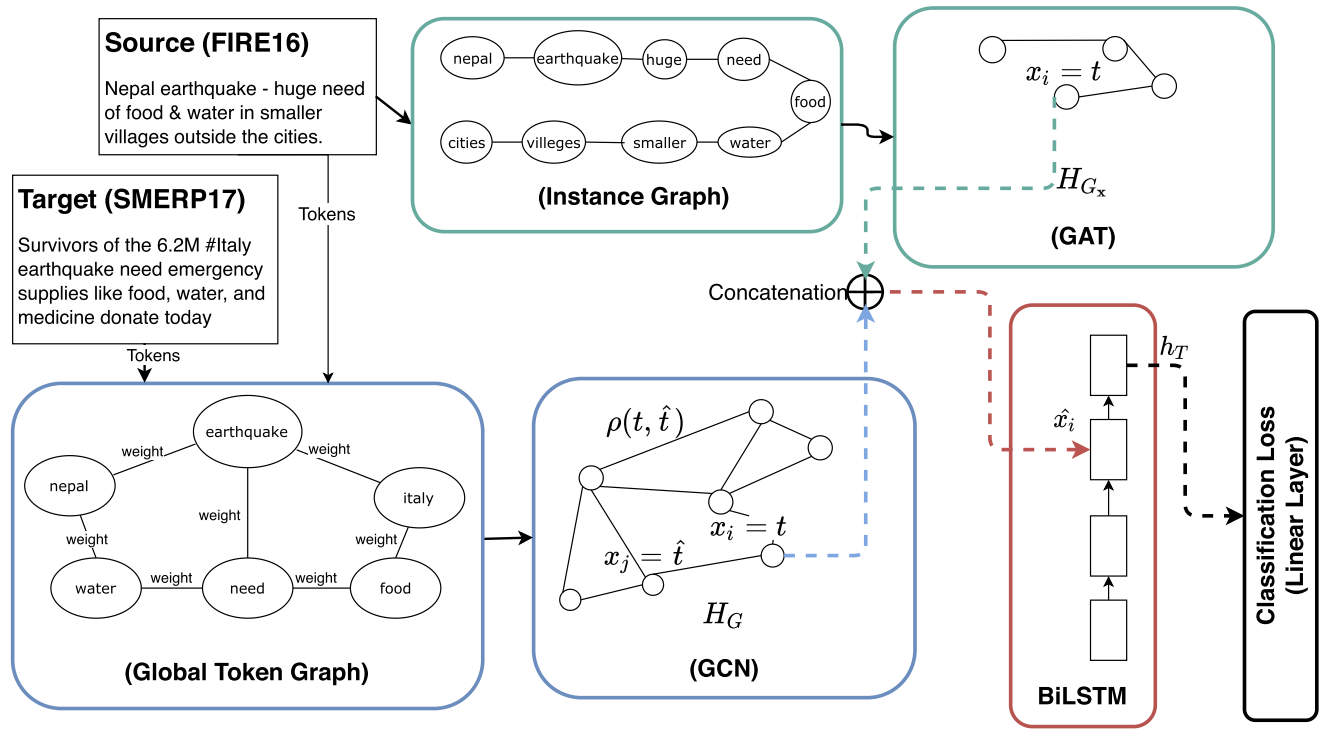
Unsupervised Domain Adaptation With Global and Local Graph Neural Networks Under Limited Supervision and Its Application to Disaster Response
IEEE Transactions on Computational Social Systems (Volume: 10, Issue: 2, April 2023) (March 2022)
Identification and categorization of social media posts generated during disasters are crucial to reduce the suffering of the affected people. However, the lack of labeled data is a significant bottleneck in learning an effective categorization system for a disaster. This motivates us to study the problem as unsupervised domain adaptation (UDA) between a previous disaster with labeled data (source) and a current disaster (target). However, if the amount of labeled data available is limited, it restricts the learning capabilities of the model. To handle this challenge, we use limited labeled data along with abundantly available unlabeled data, generated during a source disaster to propose a novel two-part graph neural network (GNN). The first part extracts domain-agnostic global information by constructing a token-level graph across domains and the second part preserves local instance-level semantics. In our experiments, we show that the proposed method outperforms state-of-the-art techniques by 2.74% weighted F1 score on average on two standard public datasets in the area of disaster management. We also report experimental results for granular actionable multilabel classification datasets in disaster domain for the first time, on which we outperform BERT by 3.00% on average w.r.t. weighted F1. Additionally, we show that our approach can retain performance when minimal labeled data are available.
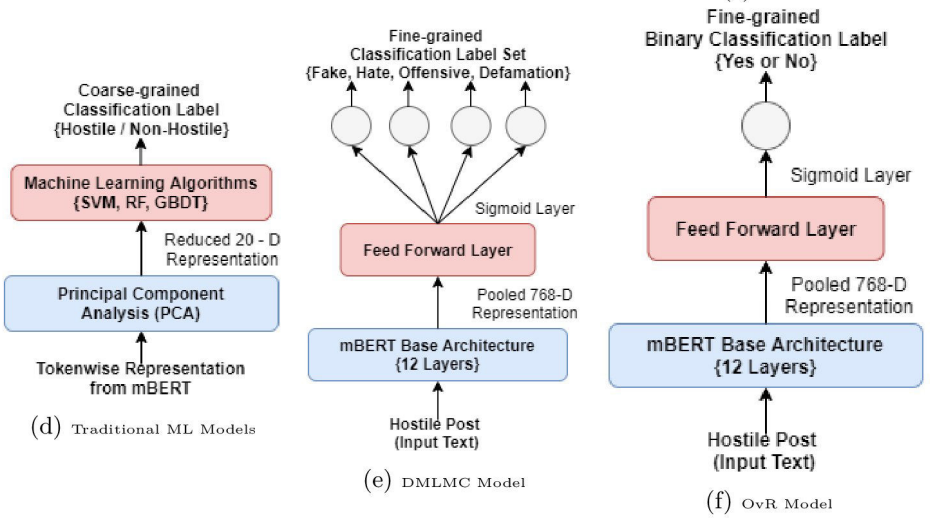
Coarse and Fine-Grained Hostility Detection in Hindi Posts using Fine Tuned Multilingual Embeddings
CONSTRAIN 2021 (Workshop on Combating Online Hostile Posts in Regional Languages during Emergency Situation) (March 2021)
Due to the wide adoption of social media platforms like Facebook, Twitter, etc., there is an emerging need of detecting online posts that can go against the community acceptance standards. The hostility detection task has been well explored for resource-rich languages like English, but is unexplored for resource-constrained languages like Hindi due to the unavailability of large suitable data. We view this hostility detection as a multi-label multi-class classification problem. We propose an effective neural network-based technique for hostility detection in Hindi posts. We leverage pre-trained multilingual Bidirectional Encoder Representations of Transformer (mBERT) to obtain the contextual representations of Hindi posts. We have performed extensive experiments including different pre-processing techniques, pre-trained models, neural architectures, hybrid strategies, etc. Our best performing neural classifier model includes One-vs-the-Rest approach where we obtained 92.60%, 81.14%, 69.59%, 75.29% and 73.01% F1 scores for hostile, fake, hate, offensive, and defamation labels respectively. The proposed model (https://github.com/Arko98/Hostility-Detection-in-Hindi-Constraint-2021) outperformed the existing baseline models and emerged as the state-of-the-art model for detecting hostility in the Hindi posts.
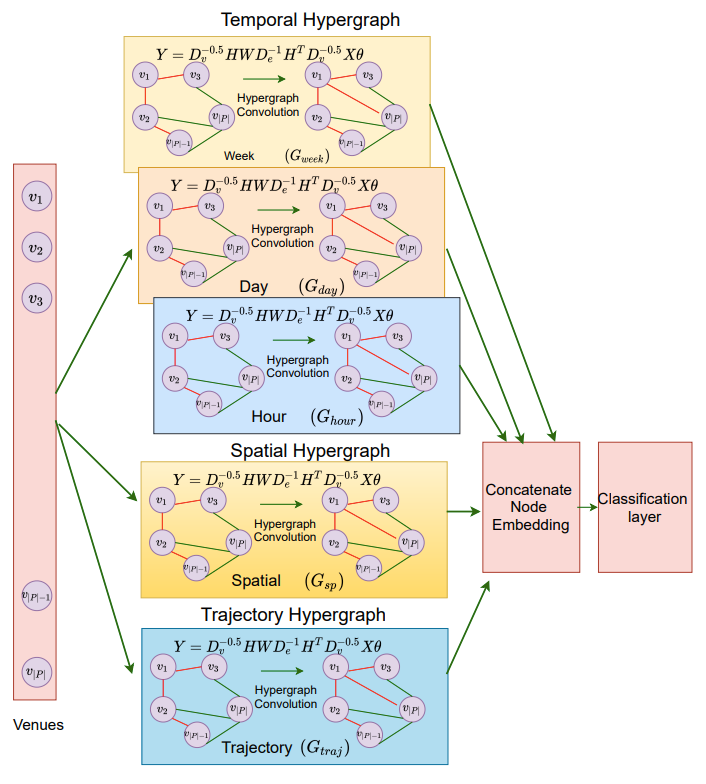
Multi-view Hypergraph Convolution Network for Semantic Annotation in LBSNs
ASONAM 2021: Proceedings of the 2021 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining (November 2021)
Semantic characterization of the Point-of-Interest (POI) plays an important role for modeling location-based social networks and various related applications like POI recommendation, link prediction etc. However, semantic categories are not available for many POIs which makes this characterization difficult. Semantic annotation aims to predict such missing categories of POIs. Existing approaches learn a representation of POIs using graph neural networks to predict semantic categories. However, LBSNs involve complex and higher order mobility dynamics. These higher order relations can be captured effectively by employing hypergraphs. Moreover, visits to POIs can be attributed to various reasons like temporal characteristics, spatial context etc. Hence, we propose a Multi-view Hypergraph Convolution Network (Multi-HGCN) where we learn POI representations by considering multiple hypergraphs across multiple views of the data. We build a comprehensive model to learn the POI representation capturing temporal, spatial and trajectorybased patterns among POIs by employing hypergraphs. We use hypergraph convolution to learn better POI representation by using spectral properties of hypergraph. Experiments conducted on three real-world datasets show that the proposed approach outperforms the state-of-the-art approaches.
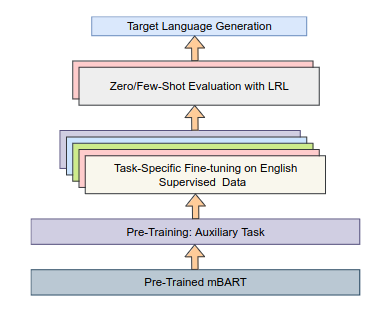
ZmBART: An Unsupervised Cross-lingual Transfer Framework for Language Generation
Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021 (August 2021)
Despite the recent advancement in NLP research, cross-lingual transfer for natural language generation is relatively understudied. In this work, we transfer supervision from high resource language (HRL) to multiple lowresource languages (LRLs) for natural language generation (NLG). We consider four NLG tasks (text summarization, question generation, news headline generation, and distractor generation) and three syntactically diverse languages, i.e., English, Hindi, and Japanese. We propose an unsupervised crosslingual language generation framework (called ZmBART) that does not use any parallel or pseudo-parallel/back-translated data. In this framework, we further pre-train mBART sequence-to-sequence denoising auto-encoder model with an auxiliary task using monolingual data of three languages. The objective function of the auxiliary task is close to the target tasks which enriches the multi-lingual latent representation of mBART and provides good initialization for target tasks. Then, this model is fine-tuned with task-specific supervised English data and directly evaluated with low-resource languages in the Zero-shot setting. To overcome catastrophic forgetting and spurious correlation issues, we applied freezing model component and data argumentation approaches respectively. This simple modeling approach gave us promising results. We experimented with few-shot training (with 1000 supervised data-points) which boosted the model performance further. We performed several ablations and cross-lingual transferability analysis to demonstrate the robustness of ZmBART.

Hi-DST: A Hierarchical Approach for Scalable and Extensible Dialogue State Tracking
Proceedings of the 22nd Annual Meeting of the Special Interest Group on Discourse and Dialogue (July 2021)
Dialogue State Tracking (DST) is a sub-task of task-based dialogue systems where the user intention is tracked through a set of (domain, slot, slot-value) triplets. Existing DST models can be difficult to extend for new datasets with larger domains/slots mainly due to either of the two reasons- i) prediction of domain-slot as a pair, and ii) dependency of model parameters on the number of slots and domains. In this work, we propose to address these issues using a Hierarchical DST (Hi-DST) model. At a given turn, the model first detects a change in domain followed by domain prediction if required. Then it decides suitable action for each slot in the predicted domains and finds their value accordingly. The model parameters of Hi-DST are independent of the number of domains/slots. Due to the hierarchical modeling, it achieves O(|M|+|N|) belief state prediction for a single turn where M and N are the set of unique domains and slots respectively. We argue that the hierarchical structure helps in the model explainability and makes it easily extensible to new datasets. Experiments on the MultiWOZ dataset show that our proposed model achieves comparable joint accuracy performance to state-of-the-art DST models.
Semi-Supervised Granular Classification Framework for Resource Constrained Short-texts: Towards Retrieving Situational Information During Disaster Events
WebSci 2020: 12th ACM Conference on Web Science (July 2020)
During the time of disasters, lots of short-texts are generated containing crucial situational information. Proper extraction and identification of situational information might be useful for various rescue and relief operations. Few specific types of infrequent situational information might be critical. However, obtaining labels for those resource-constrained classes is challenging as well as expensive. Supervised methods pose limited usability in such scenarios. To overcome this challenge, we propose a semi-supervised learning framework which utilizes abundantly available unlabelled data by self-learning. The proposed framework improves the performance of the classifier for resource-constrained classes by selectively incorporating highly confident samples from unlabelled data for self-learning. Incremental incorporation of unlabelled data, as and when they become available, is suitable for ongoing disaster mitigation. Experiments on three disaster-related datasets show that such improvement results in overall performance increase over standard supervised approach.
A Neural Approach for Detecting Inline Mathematical Expressions from Scientific Documents
Wiley Expert Systems (May 2020)
Scientific documents generally contain multiple mathematical expressions in them. Detecting inline mathematical expressions are one of the most important and challenging tasks in scientific text mining. Recent works that detect inline mathematical expressions in scientific documents have looked at the problem from an image processing perspective. There is little work that has targeted the problem from NLP perspective. Towards this, we define a few features and applied Conditional Random Fields (CRF) to detect inline mathematical expressions in scientific documents. Apart from this feature based approach, we also propose a hybrid algorithm that combines Bidirectional Long Short Term Memory networks (Bi-LSTM) and feature-based approach for this task. Experimental results suggest that this proposed hybrid method outperforms several baselines in the literature and also individual methods in the hybrid approach.
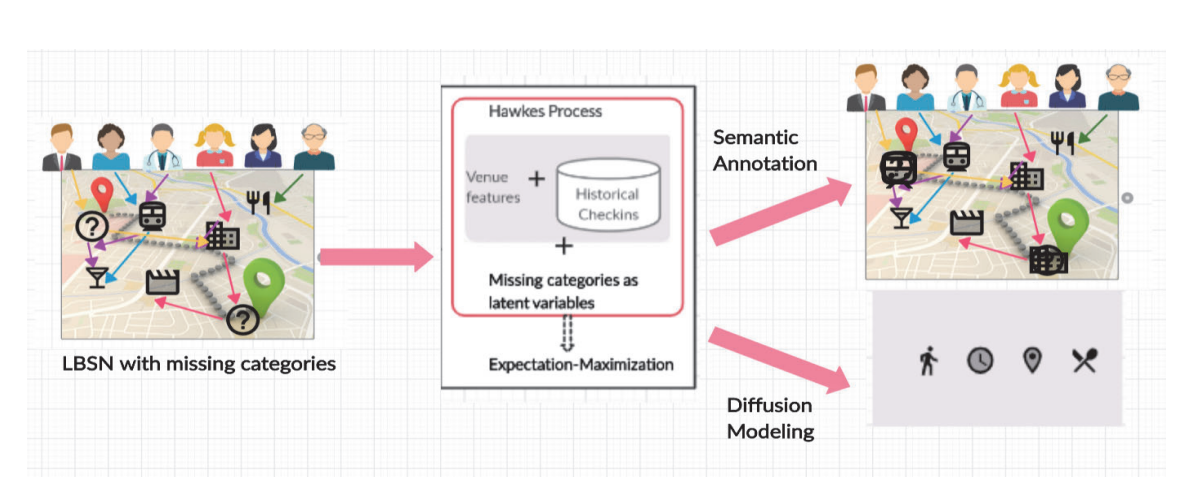
HAP-SAP: Semantic Annotation in LBSNs using Latent Spatio-Temporal Hawkes Process
SIGSPATIAL 2020: Proceedings of the 28th International Conference on Advances in Geographic Information Systems (November 2020)
The prevalence of location-based social networks (LBSNs) has eased the understanding of human mobility patterns. However, categories which act as semantic characterization of the location, might be missing for some check-ins and can adversely affect modelling the mobility dynamics of users. At the same time, mobility patterns provide cues on the missing semantic categories. In this paper, we simultaneously address the problem of semantic annotation of locations and location adoption dynamics of users. We propose our model HAP-SAP, a latent spatio-temporal multivariate Hawkes process, which considers latent semantic category influences, and temporal and spatial mobility patterns of users. The inferred semantic categories can supplement our model on predicting the next check-in events by users. Our experiments on real datasets demonstrate the effectiveness of the proposed model for the semantic annotation and location adoption modelling tasks.
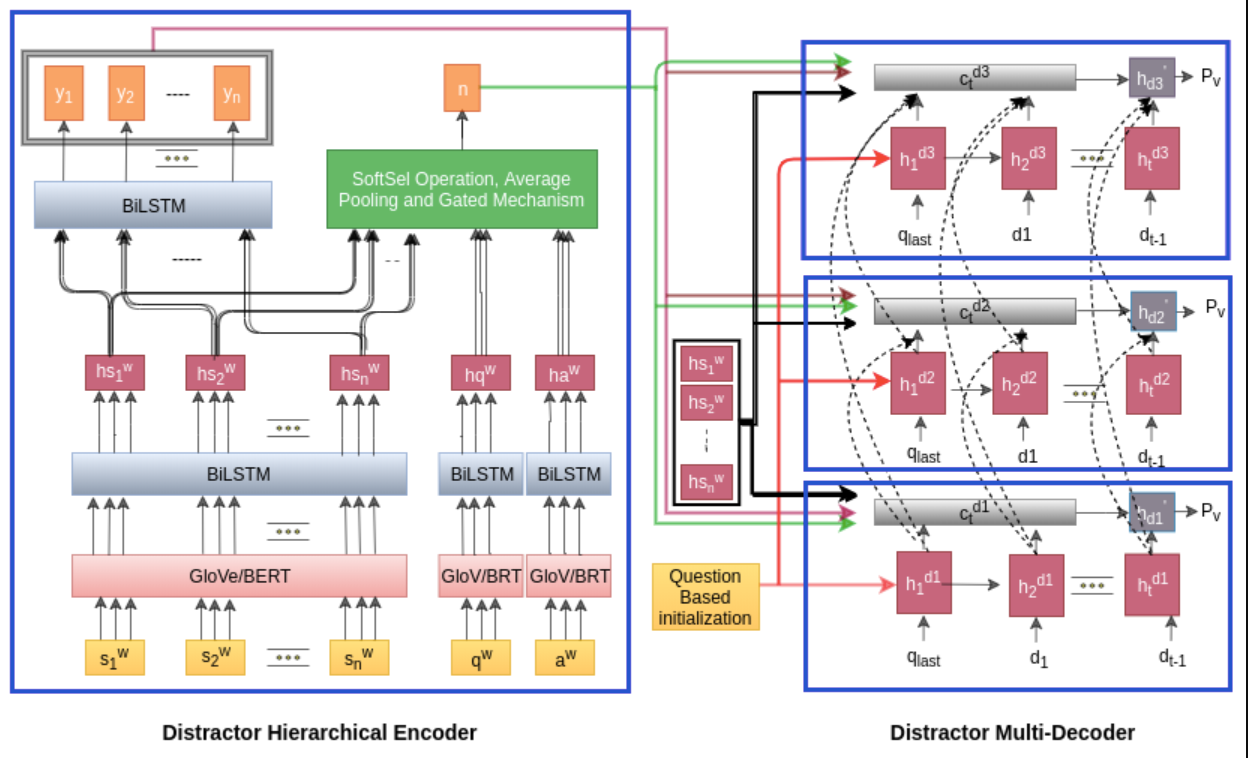
Learning to Distract: A Hierarchical Multi-Decoder Network for Automated Generation of Long Distractors for Multiple-Choice Questions for Reading Comprehension
CIKM 2020: Proceedings of the 29th ACM International Conference on Information & Knowledge Management (October 2020)
The task of generating incorrect options for multiple-choice questions is termed as distractor generation problem. The task requires high cognitive skills and is extremely challenging to automate. Existing neural approaches for the task leverage encoder-decoder architecture to generate long distractors. However, in this process two critical points are ignored - firstly, many methods use Jaccard similarity over a pool of candidate distractors to sample the distractors. This often makes the generated distractors too obvious or not relevant to the question context. Secondly, some approaches did not consider the answer in the model, which caused the generated distractors to be either answer-revealing or semantically equivalent to the answer. In this paper, we propose a novel Hierarchical Multi-Decoder Network (HMD-Net) consisting of one encoder and three decoders, where each decoder generates a single distractor. To overcome the first problem mentioned above, we include multiple decoders with a dis-similarity loss in the loss function. To address the second problem, we exploit richer interaction between the article, question, and answer with a SoftSel operation and a Gated Mechanism. This enables the generation of distractors that are in context with questions but semantically not equivalent to the answers. The proposed model outperformed all the previous approaches significantly in both automatic and manual evaluations. In addition, we also consider linguistic features and BERT contextual embedding with our base model which further push the model performance.
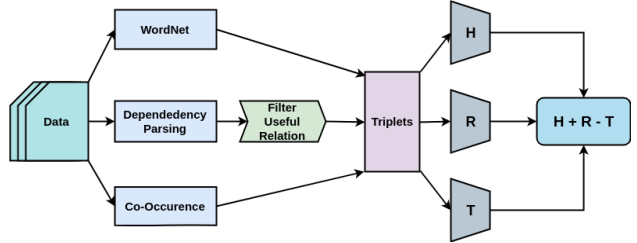
Multi-Context Information for Word Representation Learning
DocEng 2019: Proceedings of the ACM Symposium on Document Engineering 2019 (September 2019)
Word embedding techniques in literature are mostly based on Bag of Words models where words that co-occur with each other are considered to be related. However, it is not necessary for similar or related words to occur in the same context window. In this paper, we propose a new approach to combine different types of resources for training word embeddings. The lexical resources used in this work are Dependency Parse Tree and WordNet. Apart from the co-occurrence information, the use of these additional resources helps us in including the semantic and syntactic information from the text in learning the word representations. The learned representations are evaluated on multiple evaluation tasks like Semantic Textual Similarity, Word Similarity. Results of the experimental analyses highlight the usefulness of the proposed methodology.
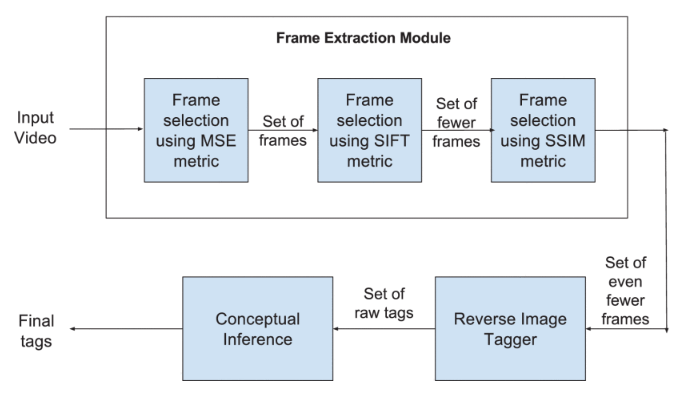
ViTag: Automatic Video Tagging Using Segmentation and Conceptual Inference
2019 IEEE Fifth International Conference on Multimedia Big Data (BigMM) (September 2019)
Massive increase in multimedia data has created a need for effective organization strategy. The multimedia collection is organized based on attributes such as domain, index-terms, content description, owners, etc. Typically, index-term is a prominent attribute for effective video retrieval systems. In this paper, we present a new approach of automatic video tagging referred to as ViTag. Our analysis relies upon various image similarity metrics to automatically extract key-frames. For each key-frame, raw tags are generated by performing reverse image tagging. The final step analyzes raw tags in order to discover hidden semantic information. On a dataset of 103 videos belonging to 13 domains derived from various YouTube categories, we are able to generate tags with 65.51% accuracy. We also rank the generated tags based upon the number of proper nouns present in it. The geometric mean of Reciprocal Rank estimated over the entire collection has been found to be 0.873.
Get me the best: predicting best answerers in community question answering sites
RecSys 2018: Proceedings of the 12th ACM Conference on Recommender Systems (September 2018)
There has been a massive rise in the use of Community Question and Answering (CQA) forums to get solutions to various technical and non-technical queries. One common problem faced in CQA is the small number of experts, which leaves many questions unanswered. This paper addresses the challenging problem of predicting the best answerer for a new question and thereby recommending the best expert for the same. Although there are work in the literature that aim to find possible answerers for questions posted in CQA, very few algorithms exist for finding the best answerer whose answer will satisfy the information need of the original Poster. For finding answerers, existing approaches mostly use features based on content and tags associated with the questions. There are few approaches that additionally consider the users' history. In this paper, we propose an approach that considers a comprehensive set of features including but not limited to text representation, tag based similarity as well as multiple user-based features that target users' availability, agility as well as expertise for predicting the best answerer for a given question. We also include features that give incentives to users who answer less but more important questions over those who answer a lot of questions of less importance. A learning to rank algorithm is used to find the weight of each feature. Experiments conducted on a real dataset from Stack Exchange show the efficacy of the proposed method in terms of multiple evaluation metrics for accuracy, robustness and real time performance.
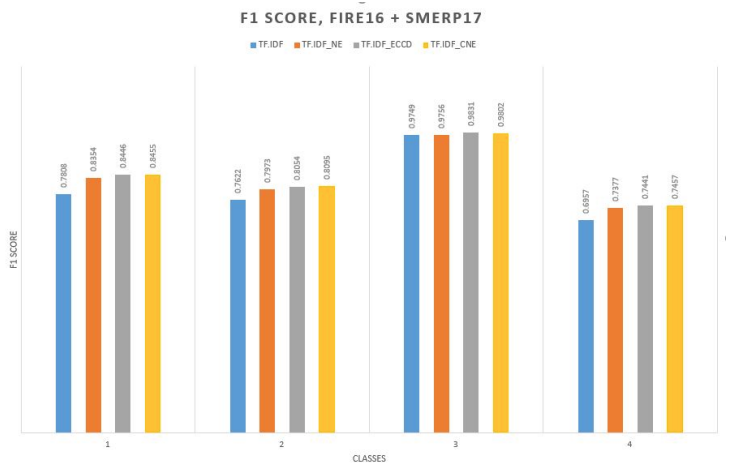
Class Specific TF-IDF Boosting for Short-text Classification: Application to Short-texts Generated During Disasters
WWW 2018: Companion Proceedings of the The Web Conference 2018 (April 2018)
Proper formulation of features plays an important role in short-text classification tasks as the amount of text available is very little. In literature, Term Frequency - Inverse Document Frequency (TF-IDF) is commonly used to create feature vectors for such tasks. However, TF-IDF formulation does not utilize the class information available in supervised learning. For classification problems, if it is possible to identify terms that can strongly distinguish among classes, then more weight can be given to those terms during feature construction phase. This may result in improved classifier performance with the incorporation of extra class label related information. We propose a supervised feature construction method to classify tweets, based on the actionable information that might be present, posted during different disaster scenarios. Improved classifier performance for such classification tasks can be helpful in the rescue and relief operations. We used three benchmark datasets containing tweets posted during Nepal and Italy earthquakes in 2015 and 2016 respectively. Experimental results show that the proposed method obtains better classification performance on these benchmark datasets.
Using social media for classifying actionable insights in disaster scenario
International Journal of Advances in Engineering Sciences and Applied Mathematics volume 9, pages224–237 (December 2017)
Micro-blogging sites are important source of real-time situational information during disasters such as earthquakes, hurricanes, wildfires, flood etc. Such disasters cause miseries in the lives of affected people. Timely identification of steps needed to help the affected people in such situations can mitigate those miseries to a large extent. In this paper, we focus on the problem of automated classification of disaster related tweets to a set of predefined categories. Some example categories considered are resource availability, resource requirement, infrastructure damage etc. Proper annotation of the tweets with these class information can help in timely determination of the steps needed to be taken to address the concerns of the people in the affected areas. Depending on the information category, different feature sets might be useful for proper identification of posts belonging to that category. In this work, we define multiple feature sets and use them with various supervised classification algorithms from literature to study the effectiveness of our approach in annotating the tweets with their appropriate information categories.