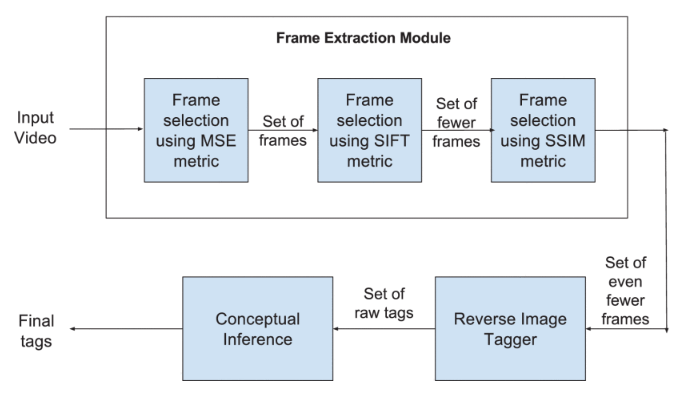
Massive increase in multimedia data has created a need for effective organization strategy. The multimedia collection is organized based on attributes such as domain, index-terms, content description, owners, etc. Typically, index-term is a prominent attribute for effective video retrieval systems. In this paper, we present a new approach of automatic video tagging referred to as ViTag. Our analysis relies upon various image similarity metrics to automatically extract key-frames. For each key-frame, raw tags are generated by performing reverse image tagging. The final step analyzes raw tags in order to discover hidden semantic information. On a dataset of 103 videos belonging to 13 domains derived from various YouTube categories, we are able to generate tags with 65.51% accuracy. We also rank the generated tags based upon the number of proper nouns present in it. The geometric mean of Reciprocal Rank estimated over the entire collection has been found to be 0.873.
@inproceedings{8919469,
author = {Patwardhan, Abhishek A. and Das, Santanu and Varshney, Sakshi and Desarkar, Maunendra Sankar and Dogra, Debi Prosad},
booktitle = {2019 IEEE Fifth International Conference on Multimedia Big Data (BigMM)},
title = {ViTag: Automatic Video Tagging Using Segmentation and Conceptual Inference},
year = {2019},
volume = {},
number = {},
pages = {271-276},
doi = {10.1109/BigMM.2019.00-12}
}