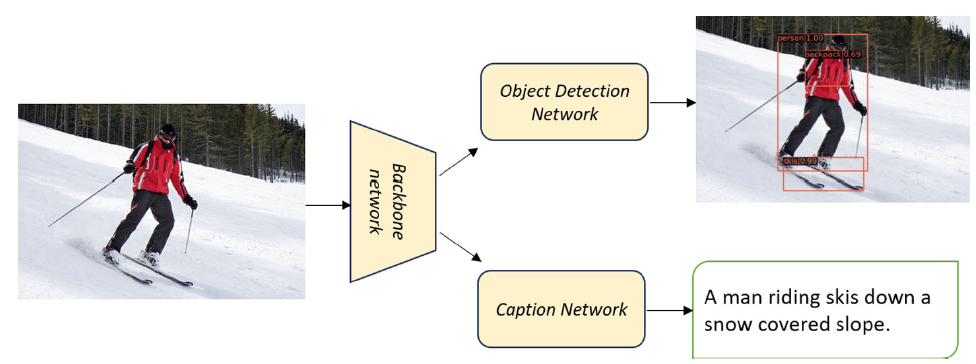
In several real-world scenarios like autonomous navigation and mobility, to obtain a better visual understanding of the surroundings, image captioning and object detection play a crucial role. This work introduces a novel multitask learning framework that combines image captioning and object detection intoa joint model. We propose TICOD, Transformer-based Image Captioning andObject Detection model for jointly training both tasks by combining the losses obtained from image captioning and object detection networks. By leveraging joint training, the model benefits from the complementary information shared AQ1between the two tasks, leading to improved performance for image captioning.Our approach utilizes a transformer-based architecture that enables end-to-end AQ2network integration for image captioning and object detection and performs bothtasks jointly. We evaluate the effectiveness of our approach through comprehensive experiments on the MS-COCO dataset. Our model outperforms the baselinesfrom image captioning literature by achieving a 3.65% improvement in BERTScore.
@inproceedings{10.1007/978-981-97-2253-2_21,
author = {Basak, Debolena and Srijith, P. K. and Desarkar, Maunendra Sankar},
title = {Transformer based Multitask Learning for Image Captioning and Object Detection},
year = {2024},
isbn = {978-981-97-2252-5},
publisher = {Springer-Verlag},
address = {Berlin, Heidelberg},
url = {https://doi.org/10.1007/978-981-97-2253-2_21},
doi = {10.1007/978-981-97-2253-2_21},
abstract = {In several real-world scenarios like autonomous navigation and mobility, to obtain a better visual understanding of the surroundings, image captioning and object detection play a crucial role. This work introduces a novel multitask learning framework that combines image captioning and object detection into a joint model. We propose TICOD, Transformer-based Image Captioning and Object Detection model for jointly training both tasks by combining the losses obtained from image captioning and object detection networks. By leveraging joint training, the model benefits from the complementary information shared between the two tasks, leading to improved performance for image captioning. Our approach utilizes a transformer-based architecture that enables end-to-end network integration for image captioning and object detection and performs both tasks jointly. We evaluate the effectiveness of our approach through comprehensive experiments on the MS-COCO dataset. Our model outperforms the baselines from image captioning literature by achieving a 3.65\% improvement in BERTScore.},
booktitle = {Advances in Knowledge Discovery and Data Mining: 28th Pacific-Asia Conference on Knowledge Discovery and Data Mining, PAKDD 2024, Taipei, Taiwan, May 7–10, 2024, Proceedings, Part II},
pages = {260–272},
numpages = {13},
keywords = {Transformer, Multitask Learning, Image Captioning, Object Detection},
location = {Taipei, Taiwan}
}