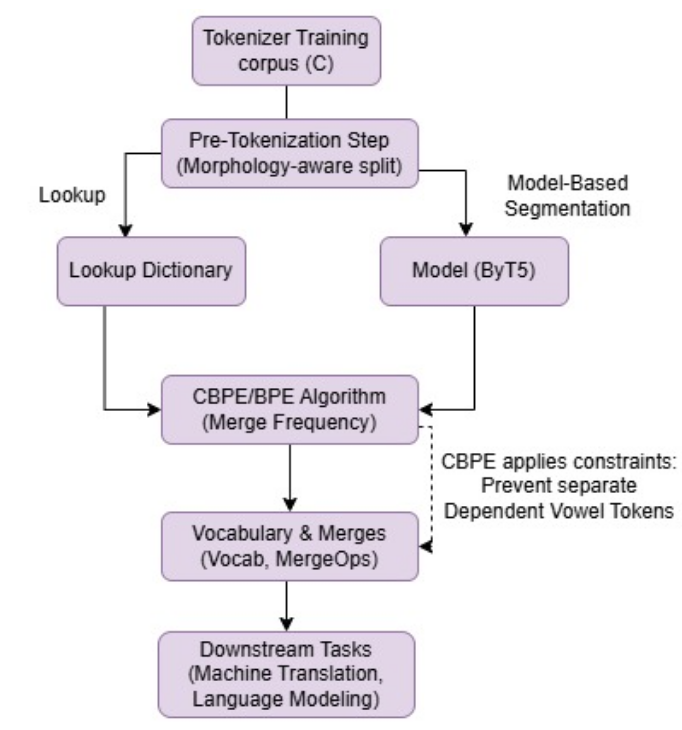
Tokenization is a crucial step in NLP, especially with the rise of large language models (LLMs), impacting downstream performance, computational cost, and efficiency. Existing LLMs rely on the classical Byte-pair Encoding (BPE) algorithm for subword tokenization that greedily merges frequent character bigrams, often leading to segmentation that does not align with linguistically meaningful units. To address this, we propose morphology-aware segmentation as a pre-tokenization step before applying BPE. To facilitate morphology-aware segmentation, we create a novel dataset for Hindi and Marathi, incorporating sandhi splitting to enhance the subword tokenization. Experiments on downstream tasks show that morphologically grounded tokenization improves machine translation and language modeling performance. Additionally, to handle the dependent vowels common in syllable-based writing systems used by Indic languages, we propose Constrained BPE (CBPE), an extension to the standard BPE algorithm incorporating script-specific constraints. In particular, CBPE handles dependent vowels to form a cohesive unit with other characters instead of occurring as a single unit. Our results show that CBPE achieves a 1.68% reduction in fertility scores while maintaining comparable or improved downstream performance in machine translation and language modeling, offering a computationally efficient alternative to standard BPE. Moreover, to evaluate segmentation across different tokenization algorithms, we introduce a new human evaluation metric, \textit{EvalTok}, enabling more human-grounded assessment.
@inproceedings{noauthor_morphtok_2025,
title = {{MorphTok}: {Morphologically} {Grounded} {Tokenization} for {Indic} languages},
shorttitle = {{MorphTok}},
url = {https://openreview.net/forum?id=32wHtvZOqH},
abstract = {Tokenization is a crucial step in NLP, especially with the rise of large language models (LLMs), impacting downstream performance, computational cost, and efficiency. Existing LLMs rely on the classical Byte-pair Encoding (BPE) algorithm for subword tokenization that greedily merges frequent character bigrams, often leading to segmentation that does not align with linguistically meaningful units. To address this, we propose morphology-aware segmentation as a pre-tokenization step before applying BPE. To facilitate morphology-aware segmentation, we create a novel dataset for Hindi and Marathi, incorporating sandhi splitting to enhance the subword tokenization. Experiments on downstream tasks show that morphologically grounded tokenization improves machine translation and language modeling performance. Additionally, to handle the dependent vowels common in syllable-based writing systems used by Indic languages, we propose Constrained BPE (CBPE), an extension to the standard BPE algorithm incorporating script-specific constraints. In particular, CBPE handles dependent vowels to form a cohesive unit with other characters instead of occurring as a single unit. Our results show that CBPE achieves a 1.68{\textbackslash}\% reduction in fertility scores while maintaining comparable or improved downstream performance in machine translation and language modeling, offering a computationally efficient alternative to standard BPE. Moreover, to evaluate segmentation across different tokenization algorithms, we introduce a new human evaluation metric, {\textbackslash}textit\{EvalTok\}, enabling more human-grounded assessment.},
language = {en},
urldate = {2025-07-26},
month = jun,
year = {2025},
}