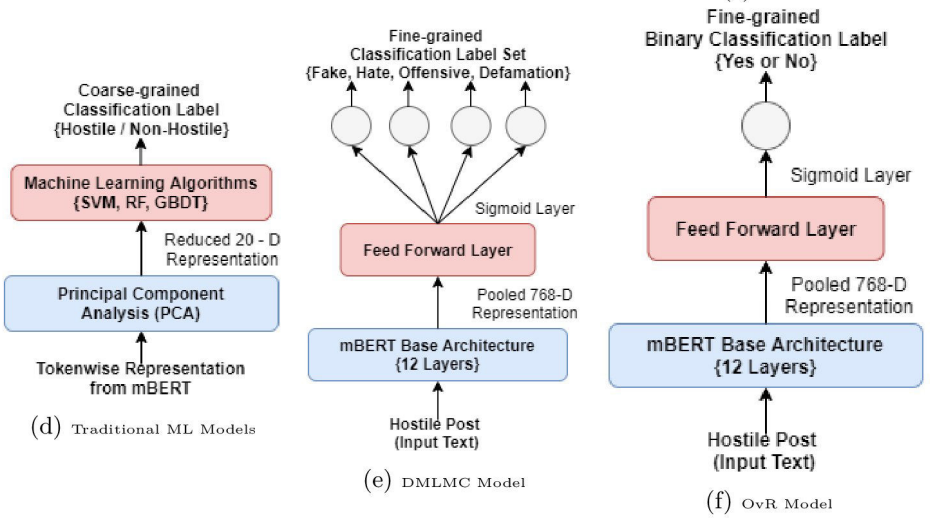
Due to the wide adoption of social media platforms like Facebook, Twitter, etc., there is an emerging need of detecting online posts that can go against the community acceptance standards. The hostility detection task has been well explored for resource-rich languages like English, but is unexplored for resource-constrained languages like Hindi due to the unavailability of large suitable data. We view this hostility detection as a multi-label multi-class classification problem. We propose an effective neural network-based technique for hostility detection in Hindi posts. We leverage pre-trained multilingual Bidirectional Encoder Representations of Transformer (mBERT) to obtain the contextual representations of Hindi posts. We have performed extensive experiments including different pre-processing techniques, pre-trained models, neural architectures, hybrid strategies, etc. Our best performing neural classifier model includes One-vs-the-Rest approach where we obtained 92.60%, 81.14%, 69.59%, 75.29% and 73.01% F1 scores for hostile, fake, hate, offensive, and defamation labels respectively. The proposed model (https://github.com/Arko98/Hostility-Detection-in-Hindi-Constraint-2021) outperformed the existing baseline models and emerged as the state-of-the-art model for detecting hostility in the Hindi posts.
@inproceedings{10.1007/978-3-030-73696-5_19,
author = {De, Arkadipta
and Elangovan, Venkatesh
and Maurya, Kaushal Kumar
and Desarkar, Maunendra Sankar},
editor = {Chakraborty, Tanmoy
and Shu, Kai
and Bernard, H. Russell
and Liu, Huan
and Akhtar, Md Shad},
title = {Coarse and Fine-Grained Hostility Detection in Hindi Posts Using Fine Tuned Multilingual Embeddings},
booktitle = {Combating Online Hostile Posts in Regional Languages during Emergency Situation},
year = {2021},
publisher = {Springer International Publishing},
address = {Cham},
pages = {201--212},
abstract = {Due to the wide adoption of social media platforms like Facebook, Twitter, etc., there is an emerging need of detecting online posts that can go against the community acceptance standards. The hostility detection task has been well explored for resource-rich languages like English, but is unexplored for resource-constrained languages like Hindi due to the unavailability of large suitable data. We view this hostility detection as a multi-label multi-class classification problem. We propose an effective neural network-based technique for hostility detection in Hindi posts. We leverage pre-trained multilingual Bidirectional Encoder Representations of Transformer (mBERT) to obtain the contextual representations of Hindi posts. We have performed extensive experiments including different pre-processing techniques, pre-trained models, neural architectures, hybrid strategies, etc. Our best performing neural classifier model includes One-vs-the-Rest approach where we obtained 92.60{\%}, 81.14{\%}, 69.59{\%}, 75.29{\%} and 73.01{\%} F1 scores for hostile, fake, hate, offensive, and defamation labels respectively. The proposed model (https://github.com/Arko98/Hostility-Detection-in-Hindi-Constraint-2021) outperformed the existing baseline models and emerged as the state-of-the-art model for detecting hostility in the Hindi posts.},
isbn = {978-3-030-73696-5}
}