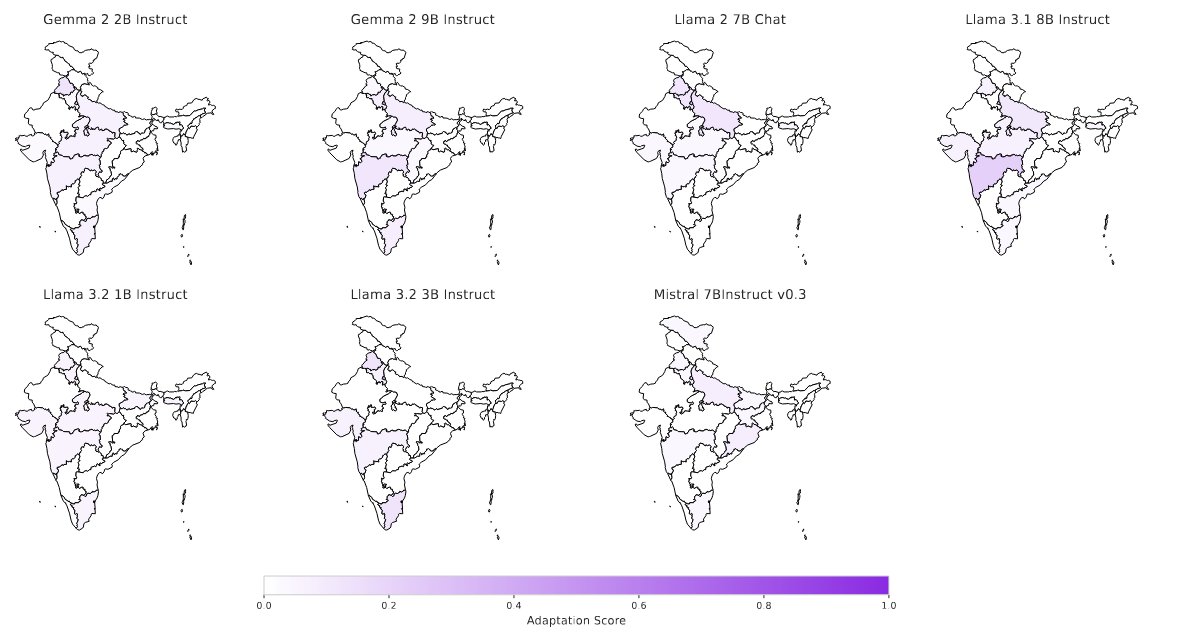
Our evaluation shows LLMs have significant disparity in adaptation of cultural concepts across Indian geographical regions (Depiction for Food facet).
Dataset and Assessment of LLMs for Cultural Text Adaptation in Indian Context
Natural Language and Information Processing Lab (NLIP)
Indian Institute of Technology Hyderabad
Hyderabad, India
TL;DR: We create a novel Cultural Specific Items Dataset for 36 Indian sub-regions. Our dataset comprises ~8k culturally relevant items belonging to 17 cultural facets.
Large language models (LLMs) are used in various applications. However, despite its wide capabilities, it is shown to lack cultural alignment and produce biased generations due to a lack of cultural knowledge and competence. Evaluation of LLMs for cultural awareness and alignment is particularly challenging due to the lack of proper evaluation metrics and the unavailability of culturally grounded datasets representing the vast complexity of cultures at the regional and sub-regional levels. Existing datasets for culture-specific items (CSIs) focus primarily on concepts at regional levels and contain several inconsistencies regarding the cultural attribution of items. To address this issue, we created a novel CSI dataset for Indian culture, belonging to 17 cultural facets. The dataset comprises ~8k cultural concepts from 36 sub-regions. To measure cultural competence, we evaluate the adaptation of LLMs to cultural text using the created CSIs, LLM-based, and human evaluations. Also, we perform quantitative analysis demonstrating selective sub-regional coverage and surface-level adaptations across all considered LLMs.
We define culture at the regional or country level, focusing on India. We created Cultural Specific Items (CSIs) that contain facet and concept pairs from various sub-regions (states and union territories) of India. We identified and selected 17 common cultural facets: food, dance, festivals, names, jewellery, places, traditions, languages, clothing, games, rituals, architectures, drinks, arts, textiles, religion, and states that reflect Indian culture. Existing datasets are limited in their coverage and often contain false positives.
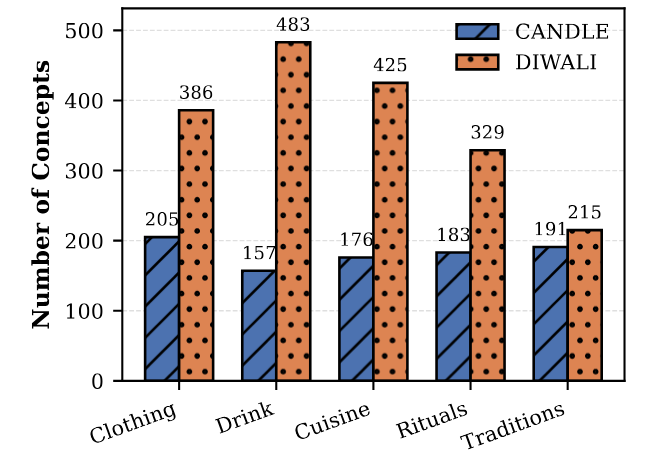
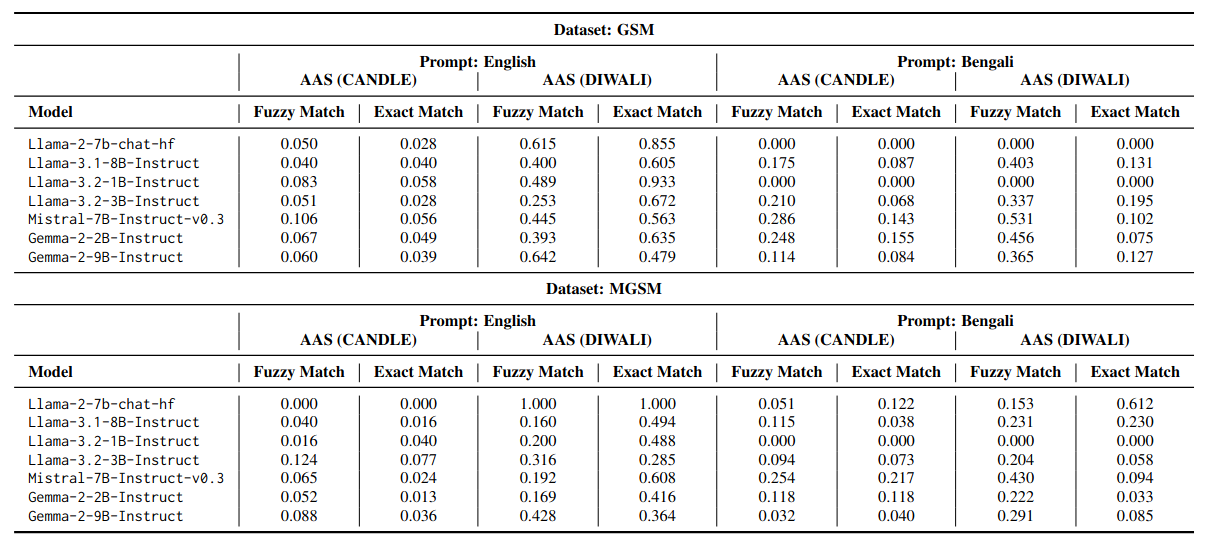
We evaluate the coverage of DIWALI on the cultural text adaptation task that transforms textual content in the source culture (American) to the target culture (Indian). To measure the adaptation quality, we define adaptation score that quantifies the quality of cultural adaptation in terms of the number of correctly replaced cultural concepts. DIWALI serves as a ground truth for cultural concepts in Indian culture. We compared DIWALI with existing CANDLE and DOSA datasets demonstrating better coverage on grade school level mathematical word problems - GSM and MGSM.
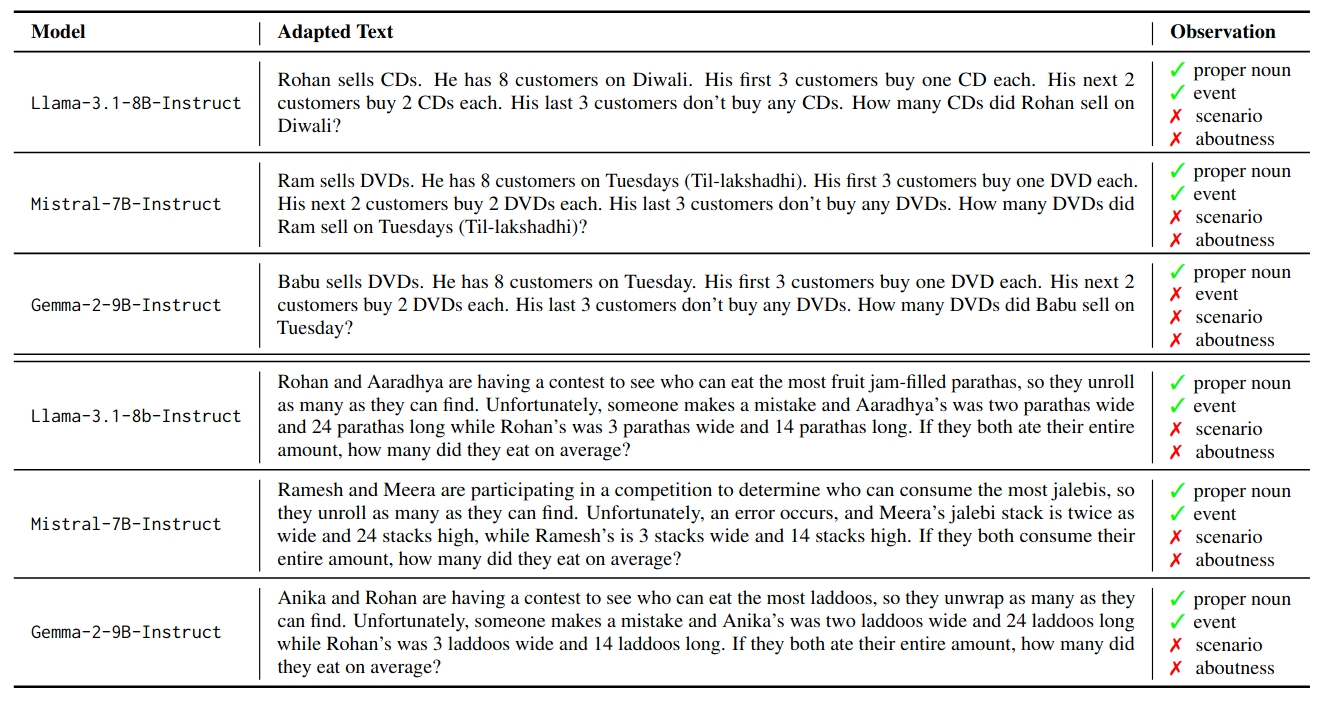
To further understand the capabilities of LLMs in terms of cultural adaptation, we analyze sub-regional coverage and adaptation levels. Our findings show that LLMs exhibit significant bias in terms of sub-regional concepts adapted at the country level. For example, concepts adapted for the food facet largely belong to Uttar Pradesh, Madhya Pradesh, Maharashtra, and Punjab. Another finding on surface versus deeper levels of cultural adaptation suggests that LLMs perform shallow adaptations. Below we show two adaptations for original texts (a) Billy sells DVDs. He has 8 customers on Tuesday. His first 3 customers buy one DVD each. His next 2 customers buy 2 DVDs each. His last 3 customers don’t buy any DVDs. How many DVDs did Billy sell on Tuesday? (b) Marcell and Beatrice are having a contest to see who can eat the most fruit roll-ups, so they unroll as many as they can find. Unfortunately, someone makes a mistake and Beatrice's was two roll-ups wide and 24 rolls up long while Marcell's was 3 roll-ups wide and 14 roll-ups long. If they both ate their entire amount, how many did they eat on average?
TBA