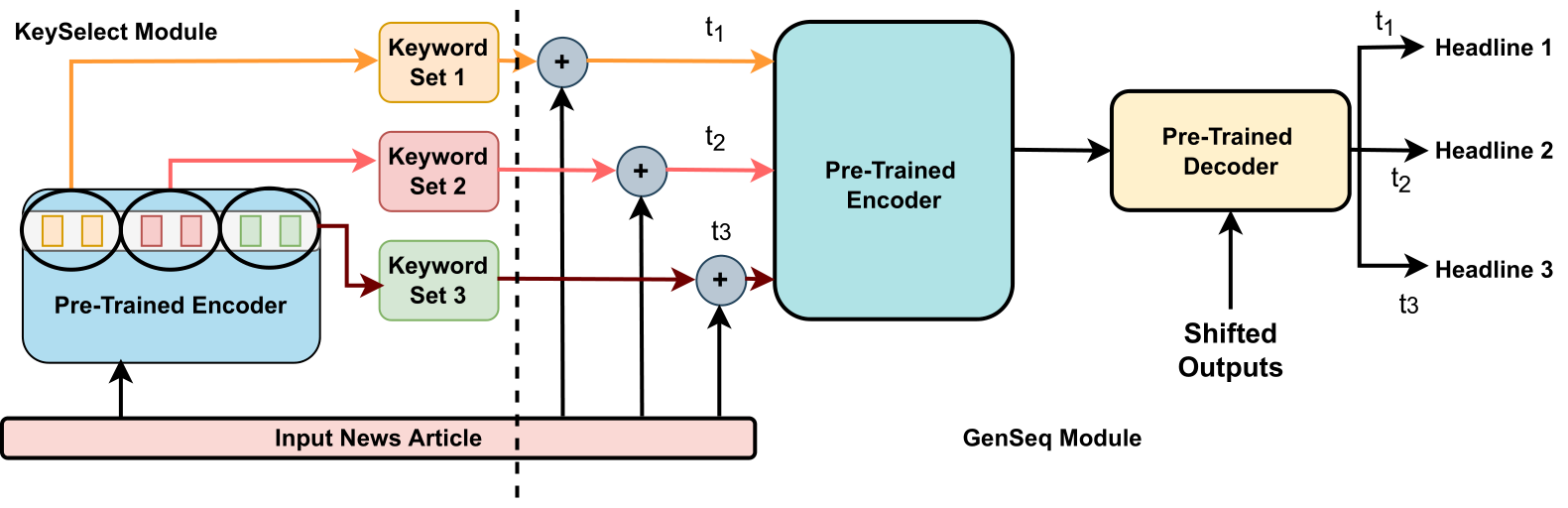
Diverse headline generation is an NLP task where given a news article, the goal is to generate multiple headlines that are true to the content of the article, but are different among themselves. This task aims to exhibit and exploit semantically similar one-to-many relationships between a source news article and multiple target headlines. Towards this, we propose a novel model called DIVHSK. It has two components: KEYSELECT for selecting the important keywords, and SEQGEN, for finally generating the multiple diverse headlines. In KEYSELECT, we cluster the self-attention heads of the last layer of the pre-trained encoder and select the mostattentive theme and general keywords from the source article. Then, cluster-specific keyword sets guide the SEQGEN, a pre-trained encoderdecoder model, to generate diverse yet semantically similar headlines. The proposed model consistently outperformed existing literature and our strong baselines and emerged as a stateof-the-art model. Additionally, We have also created a high-quality multi-reference headline dataset from news articles
@inproceedings{e-etal-2023-divhsk,
title = {{D}iv{HSK}: Diverse Headline Generation using Self-Attention based Keyword Selection},
author = {E, Venkatesh and
Maurya, Kaushal and
Kumar, Deepak and
Desarkar, Maunendra Sankar},
booktitle = {Findings of the Association for Computational Linguistics: ACL 2023},
month = jul,
year = {2023},
address = {Toronto, Canada},
publisher = {Association for Computational Linguistics},
url = {https://aclanthology.org/2023.findings-acl.118},
pages = {1879--1891},
abstract = {Diverse headline generation is an NLP task where given a news article, the goal is to generate multiple headlines that are true to the content of the article but are different among themselves. This task aims to exhibit and exploit semantically similar one-to-many relationships between a source news article and multiple target headlines. Toward this, we propose a novel model called DIVHSK. It has two components:KEYSELECT for selecting the important keywords, and SEQGEN, for finally generating the multiple diverse headlines. In KEYSELECT, we cluster the self-attention heads of the last layer of the pre-trained encoder and select the most-attentive theme and general keywords from the source article. Then, cluster-specific keyword sets guide the SEQGEN, a pre-trained encoder-decoder model, to generate diverse yet semantically similar headlines. The proposed model consistently outperformed existing literature and our strong baselines and emerged as a state-of-the-art model. We have also created a high-quality multi-reference headline dataset from news articles.}
}