TL;DR:
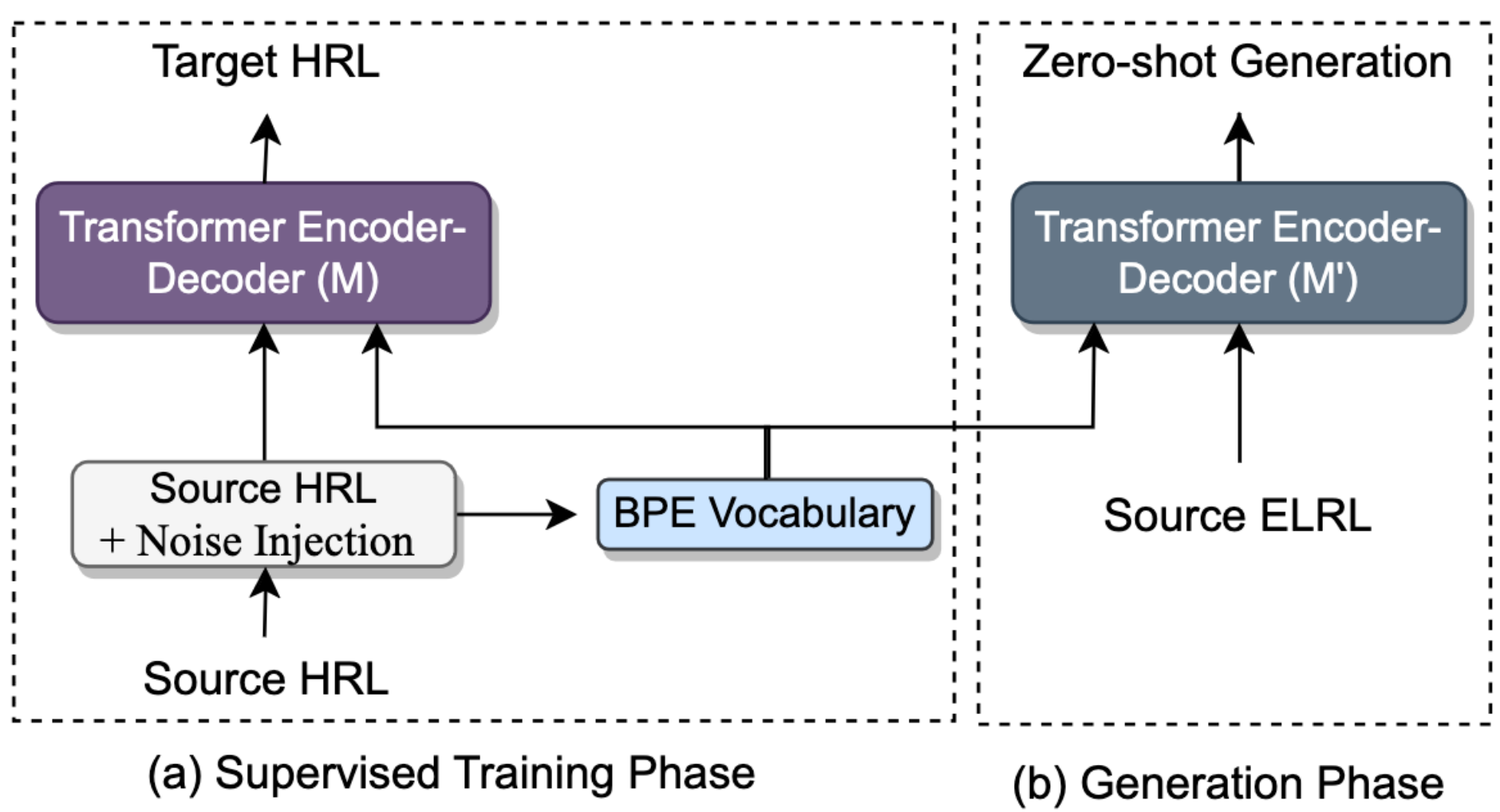
We address the task of machine translation(MT) from extremely low-resource language(ELRL) to English by leveraging cross-lingualtransfer from closely-related high-resourcelanguage (HRL). The development of an MTsystem for ELRL is challenging because theselanguages typically lack parallel corpora andmonolingual corpora, and their representationsare absent from large multilingual languagemodels. Many ELRLs share lexical similaritieswith some HRLs, which presents a novelmodeling opportunity. However, existingsubword-based neural MT models do notexplicitly harness this lexical similarity, as theyonly implicitly align HRL and ELRL latentembedding space. To overcome this limitation,we propose a novel, CHARSPAN, approachbased on character-span noise augmentationinto the training data of HRL. This serves asa regularization technique, making the modelmore robust to lexical divergences betweenthe HRL and ELRL, thus facilitating effectivecross-lingual transfer. Our method significantlyoutperformed strong baselines in zero-shotsettings on closely related HRL and ELRL pairsfrom three diverse language families, emergingas the state-of-the-art model for ELRLs.
@misc{maurya2024charspanutilizinglexicalsimilarity,
title = {CharSpan: Utilizing Lexical Similarity to Enable Zero-Shot Machine Translation for Extremely Low-resource Languages},
author = {Kaushal Kumar Maurya and Rahul Kejriwal and Maunendra Sankar Desarkar and Anoop Kunchukuttan},
year = {2024},
eprint = {2305.05214},
archiveprefix = {arXiv},
primaryclass = {cs.CL},
url = {https://arxiv.org/abs/2305.05214}
}